The Single Point of Failure
Recently I’ve been mentoring a startup in the Boulder area that processes large amounts of data real time. They have a Service Oriented Achitecture in which backend services do most of the data processing. While they were still in beta they were getting spikes of traffic, which led us to a conversation that went like:
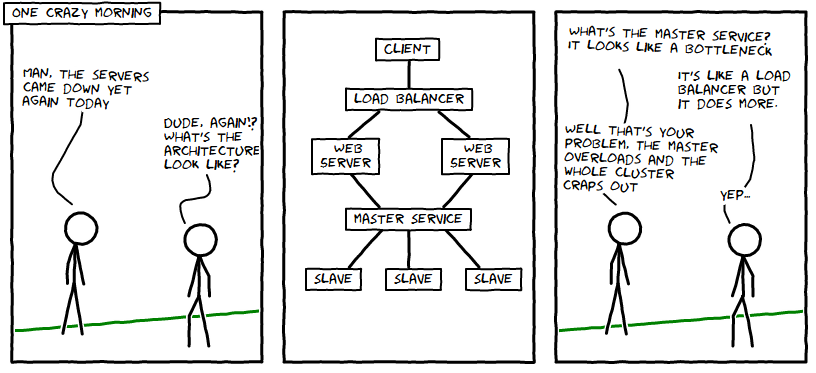
Intro to Distributed Systems
The architecture above is the naive approach when designing your first distributed system. There are 2+ web servers to handle traffic that gets funneled into a single “master service”. As the cartoon points out, this is an inherent bottleneck. The diagram has an hour glass shape, indicating where the bottleneck is. If traffic spikes, the master will fall over and the slave functionality will be inaccessible until the master comes back online.
The fact that the master is manually configured as master is the source of many problems. If the master dies, none of the slaves have the latitude to step up and become master, so you have to wait for the sysadmin to manually bring the master back online. There’s a quick solution to this.
A Less Naive Solution
MongoDB solves this problem by automatically electing a new master. It has replication in place such that a majority of nodes should have the latest changes. (Note: this isn’t actually true, which is why MongoDB has been under a lot of scrutiny lately; assume for now that it is true)
In MongoDB, when a master dies, the slaves automatically detect the failure and initiate an election for a new master. Depending on the implementation and circumstances, the time it takes to detect the failure in the master until a new master is elected and operating can be anywhere from 1-2 seconds all the way up to minutes. (God help us if we’re completely inoperable for entire minutes).
There are mainly two problems with this architecture. First, the cluster can’t do anything while it has no master. The master is required to coordinate load distribution (efficiency) and consistency - two attributes that are crucial to most distributed systems. Until there’s another master, we can’t guarantee consistency, and we have no way to distribute work fairly, so the whole cluster is left idle.
The second problem is that masters are inherent bottlenecks. In the case of the “master service” in the comic, the master is keeping track of traffic and usage stats and distributing work accordingly. Another way to say that is “the master is keeping the distribution of load consistent”. In this architecture, all information that affects consistency (new jobs coming in) must be funneled throught the master. Therefore, the entire system is limited by how fast the master can distribute work.
The Optimal Approach
There best way to solve this problem is to make it operate without a master.
There is several ways to do this, but I’m most fond of how Cassandra does it.
A Cassandra cluster is setup in a ring - so called because all nodes are
considered equal to each other (think King Aurthur’s round table). When a
client wants to connect to a Cassandra cluster, it connects to any node in
the ring. All create, update, or delete operations are replicated to all
other nodes, so every node contains a full view of the data.
Contrast the ring architecture with the master-slave architecture:
| Master-Slave | Ring | |
|---|---|---|
| Connect to | Master for writes; Any node for reads |
Any node for writes or reads |
| When node dies | Wait for reelection | Connect a different node |
| When we need more throughput | N/A | Connect to another node |
If we ever need the cluster to do more work, we just add another node. This is why Cassandra can claim linear scaling. As the amount of work increases, the amount of resources Cassandra needs to handle the work also increases linearly. This is ideal (unless someone knows how to scale hyperbolically).
In our data processing example in the comic, the ring architecture means that the Web Servers (clients) connect to any of the workers (slaves) directly; there is no master. If the worker is processing too much work, it redirects the Web Server (client) to another worker. All workers replicate metadata about their knowledge of the cluster to all other workers. The metadata would probably include a list of all workers along with their current loads and capacities.
Summary
To bring it all back together, using a master-slave architecture in a distributed system is an anti-pattern. It introduces bottlenecks and potential for disrupting the entire system. While it seems to make sense at first, it’s more destructive than helpful. Consider using an alternative to master-slave architecture. One such alternative is the Ring that Cassandra uses.