Does Prompt Caching Make RAG Obsolete?

Anthropic announced prompt caching today. They make some bold claims, like reducing costs by “up to 90%”. That’s nuts, how realistic is it? It completely depends on how you use your LLM.
First of all, prompt caching, what is it?
The prompt is the instructions to the LLM, but it can also contain examples of the task being done. More commonly, we’ll dump an entire document in the prompt and ask questions about it. The follow-up conversation is not part of the prompt.
I assume they do this by caching portions of the attention calculation. Attention is a n2
operation, so you can imagine the quatity of caculation as an area.
If your prompt is 80% of the total conversation that you’re sending to the LLM, the cached portion is fairly big! (Lighter green is cached, darker green is not cached)
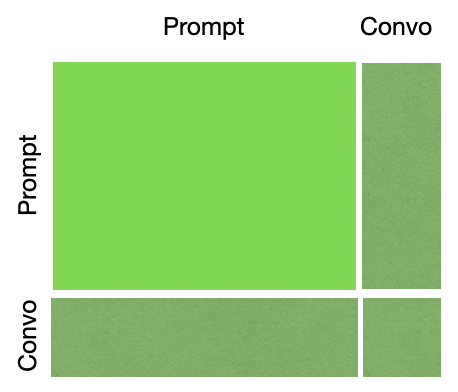
The price is structured so that it costs a little bit more (+25%) on the first prompt, when you load/invalidate the cache. But it costs dramatically less (-90%) when you reuse the cache.
How do you use this?
Don’t change your prompt. If you have a string.format() in your prompt (i.e. dynamic data), you’re going
to pay 25% more on every prompt. On the other hand, you could quickly save a ton of money if your prompt
is static.
Workloads that are going to benefit a lot:
- Chat with Document — Load up one or two documents (e.g. an employment contract & employee handbook) and ask quesions
- Machine Learning — Provide several examples and solutions to a problem you need to solve, like you would with XGBoost
- Programming — This is huge. This effectively 10x’s the context size that can be used, to keep the price the same as before
- Long Conversations — The payoff happens pretty fast, so I imagine ChatGPT-style applications will probably want to introduce caching to save on costs
What about RAG?
Okay, does it help you if you’re data is in a vector store? Well no, we already talked about how if you’re
using string.format() it’s going to make it more expensive. But…what if we replaced the vector store anyway?
What if you just included the entire database in the prompt? Well, if it’s small that could work. However, it would cost about $0.10 per megabyte, whereas most databases will store data for somewhere on the order of $0.01 per gigabyte, that’s something like 10,000x more expensive than just using a database.
Again, this might be fine with you. The costs will ceratainly come down over time, and it’ll be suitable for more and more people. However, there’s still a lot of security & productivity reasons to do RAG via a knowledge graph instead of a vector store. I wrote about it here. I think a lot of that discussion isn’t resolved by huge contexts. I don’t think you can reliably build safe LLM applications without the structure provided by a knowledge graph.
Knowledge graphs can be difficult to create, so I've been working on an app to make it as simple as taking notes, or pointing it at blogs or wikis. Sign up here if that sounds interesting.
Conclusion
This is a big development for a lot of LLM uses. And while it does address some RAG applications, you probably don’t want to jump to that quite yet. What is certain, is LLM programming just got a bit more complex.