What is entropix doing?

Entropix has been getting a ton of buzz lately. With all the hype, it’s hard to tell if there’s anything real that’s worth paying attention to.
The open source project aims to create o1-like reasoning by taking existing models, the really tiny ones, and swaps out the sampler for an algorithm based on entropy and varentropy.
No re-training, no fine-tuning, just slap some code on the last step and it starts reasoning? That’s wild. Is it real? Let’s look a bit deeper.
What is a sampler?
You know how LLMs are just predicting the next word in the sequence? Yeah, they calculate probabilities for every possible word (token) that can come next. The sampler is the heuristic or algorithm for how to choose which comes next.
There’s a few common takes, but mostly it boils down to choosing the highest probability token (the logit value, technically).
Well that sounds boring.
It does sound boring, except for some reason a whole lot of people are getting excited about it.
For example, @_xjdr posted this output:

Okay, cool, it can do math. Now what?
No! LLMs don’t do math. They just predict the next token. To so many people, it’s plainly obvious that LLMs can’t do math, yet here we go.
This particular one has been tripping up a lot of bigger LLMs. The trouble is, LLMs do pattern matching. They’re a quick thinker that glances at a problem and says the first thing that comes to mind. So, in the case of 9.9 vs 9.11, they look a bit like software version numbers, in which case 9.11 is indeed larger.
To be clear, the screenshot above is on a 1B model, one of the smallest models available yet it was out performing others 10x or 100x times it’s size.
So how does it work?
The details are still a bit hazy to me, but the concept is all about entropy & varentropy. Here’s how I understand it:
- entropy: Where I am right now. If it’s high entropy, I’m confused (I’m going to hallucinate). If it’s low entropy, I’m clear on what I’m doing next.
- varentropy: The landscape around me. If I’m confused now, look for a token that’s likely to lead me closer to clarity. Varentropy is like a slope. You can visualize this as standing on a hill, knowing you’re confused, and using varentropy to point “downhill” to a place of lower entropy.
You might be surprised to learn that LLMs know when they’re confused, but that’s been known for a little while.
It’s still fundamentally just a next-token predictor, but it’s using signals that the model is giving us to steer away from hallucinations.
From their Github readme:
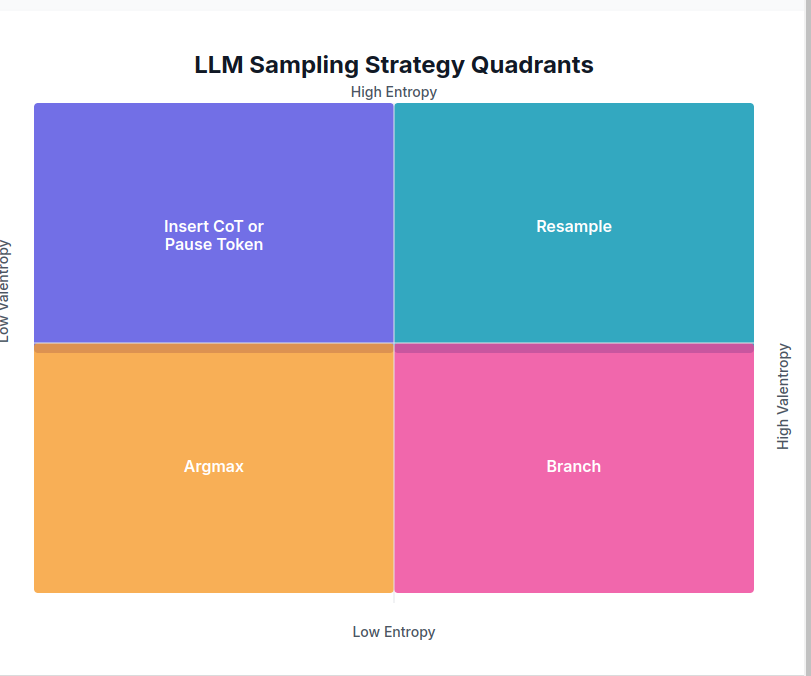
My interpretation:
- Argmax (Low, Low) — act normal
- Insert CoT or Pause Token (High entropy) — It’s not certain, but it could become so. Induce deeper thinking via traditional methods (maybe what o1 is doing?)
- Branch (High varentropy, but low entropy) — The LLM is certain of itself, but the landscape is rugged, there’s a good chance it’ll turn out badly a few tokens from now. So, let’s choose multiple paths and evaluate all paths until one seems like the winner.
- Resample (High, High) — We’re lost. Our best hope is to start over and re-roll the dice.
So, is it just guessing?
Yes, it’s still just guessing the next token, just like before. The difference is now, entropix is stacking the odds to make it less likely it’ll hallucinate.
In the example, it used very strange logic. Why did it add 0.1 to each? Yeah, I dunno bro. That’s
not how I would do it, but It’s a similar process to what we’re teaching my daughter.
If you have to add 90 + 120, you reduce it to (9 + 12) * 10, because 9 + 12 seems easier to us.
LLMs are going to take different shortcuts. Adding 0.1 to 9.9 and 9.11 makes it a little more
obvious to the LLM that we’re not talking about software versions (btw, you never add software versions, so that
operation isn’t confused).
In The Programmer’s Brain, Feylienne talks about how expert chess players and programmers have larger patterns memorized. So when an expert programmer is thinking about code, they’re not working with individual characters, they’re thinking in terms of larger patterns — function calls, design patterns, etc.
I think that’s what’s going on here. If the LLM has some fragment of a math problem memorized (e.g.,
for us 9+12), it just spits out the answer. Entropix is giving the LLM the ability to ignore these patterns and
listen to its own uncertainty, just like an expert programmer might look at a shred of code and realize,
“uh, this looks like a for loop over an array, but it’s doing something very dumb, let’s stop and read
carefully”.
Is it really doing math?
Great question. A simple answer might be, no, because completing sentences isn’t math. Then again, when you think through a math problem, that’s a long sequence of symbols strung together until the right answer emerges (if you were to write down your thought process).
I can’t comfortably convince myself in either direction. It does seem clear that it’s not doing math the same way we do math, but that makes sense, it was trained differently.
An arXiv paper hot off the press concludes that LLMs (not including entropix) aren’t doing real reasoning. On the other hand, they say it’s because LLMs just “replicate the reasoning steps observed in their training data”. If entropix is indeed allowing the LLM to not simply replicate reasoning steps, then maybe this really is the key to deeper reasoning.
This certainly needs more research.
Squeezing the juice
I love the idea of entropix because it feels like we’re squeezing every parameter of the model for all that it’s worth. In that paper about LLMs knowing their own confusion level, they point out that we could make far better utilization of an LLMs parameter count if we were able to navigate this sense of uncertainty that seems to be exuding from the models.
To some extent, the models are capturing all the right information, but we’re making them walk around like a drunk guy in the dark, hoping to stumble into the right answer. Entropix just turns the light on.
What’s next?
Last I heard, entropix is splitting the repository, one effort going toward huge models and pushing the limits for where this can go. The other is focused on local LLMs, squeezing out every last drop of intelligence.
I’ll be watching this repo. It’s not clear yet if this is the key that unlocks the next jump in model performance, but it’s certainly fun to watch.