Why is entropix important?

The buzz is there! The cooks are cooking! But what is entropix? I wrote a fluff piece here explaining it, but the most comprehensive and complete description of entropix is here.
You should think of entropix as a new framework for LLM execution that uses the model’s own signals to dynamically switch between a lot of existing LLM techniques. That dynamic part is where the magic is at.
I haven’t seen final authoritative claims, but a lot of the vagueposting on X points to significant performance gains:
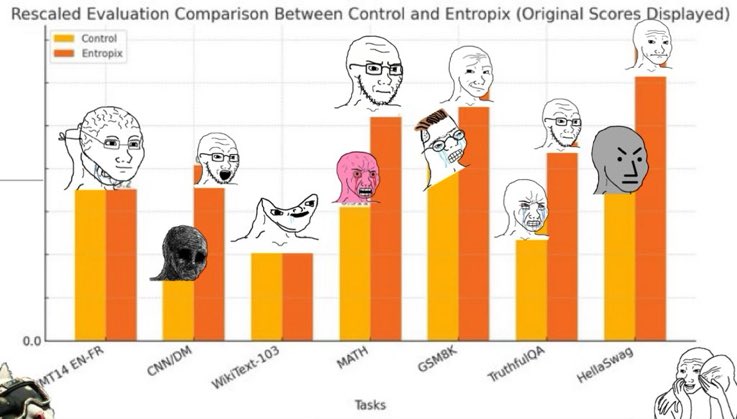
So, aside from cool graphs, why should you pay attention?
Goodbye Prompt Engineering
In the ideal state, entropix makes prompt engineering obsolete. I doubt that’s going to be true out of the gate, and maybe never, but that’s effectively where this is going.
Hallucinations happen when the model gets to a point where it’s uncertain, but the rules demand that it choose a path and continue on with boldness, even if the model isn’t feeling bold. In other words, hallucination is a behavior issue, not a knowledge issue.
Prompt engineering is the current solution, tweak the wording to convince the LLM to stay away from the uncertain states.
Entropix offers a new path. If the model feels uncertain or stuck, we can give it other options. We can drop into Chain of Thought or tweak the temperature or top-k parameters to make it more creative, whatever is needed in the moment.
In effect, entropix is automating prompt engineering. Where the prompt engineer was tweaking prompts to navigate the model into a more certain state, now it’s entropix doing the same thing, but several times throughout the evaluation depending on the present situation. It’s able to do a much better job, because it’s able to get feedback directly from the model’s internal state, and also adjust
Nerd Note: I like to compare it to JIT compilers in programming languages. e.g. Julia code can often be faster than the equivalent C/C++ code because the JIT is able to customize the program to the data that’s currently being operated on.
Beginning of a Long Road
The current entropix is a fairly crude set of heuristics. There’s already a fork for using reinforcement learning to replace the heuristics. It’s going to develop fast, it already is.
But even the strategies themselves. Up till now we’ve only considered sampling strategies that perform well globally on at least one benchmark. But with entropix, you can entertain strategies that work well in just one edge case that help the model get unstuck or look further ahead, but would otherwise hold the model back.
As good as entropix benchmarks may be, when they land, don’t take them too seriously. This can go a lot further.
Smaller Models
After o1 and now entropix, I think we’re moving into a new era where compute during inference is a better trade-off than train-time.
Entropix has been getting surprisingly decent reasoning behavior out of llama 3.2 1B. If that trend continues, why shouldn’t we run models exclusively on phones and/or IoT devices? Is it really necessary to send your data to the cloud? There’s certainly a ton of advantages, a whole lot of use cases start to open up when you don’t have to trust another company with your data.
✅ Privacy
Openness FTW
There’s a ton of buzz online around entropix. And honestly, a lot of that buzz has been translating directly into very intense collaboration. It’s unfortunate that we don’t have a paper right now, but we have something better: a fully open scientific process.
On Github, they have 10 committers with ~16 more in the PR queue. There’s a totally different implementation with corroborating results. There are forks implementing lookahead and a few other schemes. People are coming out of the woodwork to offer ideas, it’s nuts.
Normally in the scientific process, you have to wait for published replicatable results before you start to see a buzz of collaboration. But with entropix, the collaboration has been going nonstop for the last couple weeks, long before anything could be claimed with certainty. If we get nothing else from entropix, I would love to see this sort of high energy collaboration applied to more research areas.