Recursive Improvement: AI Singularity Or Just Benchmark Saturation?

A fascinating new paper shows that LLMs can recursively self-improve. They can be trained on older versions of themselves and continuously get better. This immediately made me think, “this is it, it’s the AI singularity”, that moment when AI is able to autonomously self-improve forever and become a… (well that sentence can end a lot of ways)
Off the cuff, I don’t think it’s the singularity, but if this idea takes off then it’s going to look a lot like it. More on that later.
Self-Improvement
The idea is:
- Start with a baseline model
- Use it to generate questions & answers
- Use majority voting to filter out bad answers or low-quality questions
- Train on the new corpus
- GOTO 2
Yep, it goes forever.
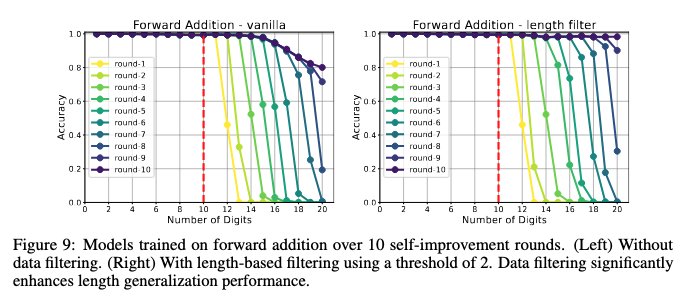
Here’s an example, multiplying numbers together, with incrementally bigger numbers.

The yellow line (round 1) indicates base performance. The top purple line (round 10) is after blindly training without filtering. That cliff on round 10 is what model collapse looks like. They call it the error avalanche.
But performance doesn’t drop off immediately, it remains perfect for a couple rounds before dropping off. This is the key insight. If you generate problems that are just a little harder, then you can easily filter and keep pushing performance further.
When a single LLM evaluates correctness, the probability of a mistake is somewhat high. But with majority voting, as you add voters that probability is driven down toward zero. At some point it’s low enough to make it a cost effective strategy.
(No, they didn’t clarify how many voters are needed)
Limitations
Okay, what can’t this do?
The problems have to have an incremental nature. e.g. They multiplied larger and larger numbers, or tweaked paths through a maze to make them slightly more complex. If you can’t break problems down, they likely won’t work for this.
Also, problems have to have a clear answer. Or at least, the voters should be able to unambiguously vote on the correctness of an answer.
So this might not work well with creative writing, where stories aren’t clearly right or wrong. And even if they were it’s not easy to make a story only slightly more complex.
Another elephant in the room — cost. Recall that R1 went to great lengths to avoid using an external LLM during RL training, mainly to control costs. But also recall that companies are scaling up to super-sized datacenters. This cost has definitely been factored in.
Benchmark Saturation
As far as I can tell, most benchmarks fit within those limitations, and so will be saturated. They’re typically clear and unambiguously correct, otherwise the questions couldn’t be used as a benchmark. My sense is that they’re typically decomposable problems, the kind that could be tweaked to be made slightly more complex.
If this recursive improvement becomes a thing, I imagine that most benchmarks are going to be quickly saturated. Saturated benchmarks are as good as no benchmarks.
It’s going to look like insane progress, but I don’t think it’s the singularity. The paper didn’t talk at all about emergent behavior. In fact it assumes that a behavior has already emerged in order to bootstrap the process. But once it’s emerged, this process can max out it’s potential.
It seems like agents might be a rich place to find problems that fit this mold well. The trouble is going to be creating benchmarks fast enough.
My hunch is that, going forward, we’ll lean on reinforcement learning (RL) to force behaviors to emerge, and then use some form of recursive self-improvement fine tuning to max out that behavior.
This year just keeps getting wilder..