Multi-Agents Are Out, PID Controllers Are In

My hottest take is that multi-agents are a broken concept and should be avoided at all cost.
My only caveat is PID controllers; A multi agent system that does a 3-step process that looks something like Plan, Act, Verify in a loop. That can work.
Everything else is a devious plan to sell dev tools.
PID Controllers
First, “PID controller” is a term used by crusty old people and nobody doing AI knows what I’m talking about, sorry.
PID controllers are used in control systems. Like if you’re designing a guidance system in an airplane, or the automation in a nuclear power plant that keeps it in balance and not melting down. It stands for “proportional–integral–derivative” which is really not helpful here, so I’m going to oversimplify a lot:
A PID controller involves three steps:
Example: Nuclear power plant
- Verify: Read sensors for temperature, pressure, power needs, etc. and inform the “Plan” step
- Plan: Calculate how much to move the control rods to keep the system stable, alive, and not melting down
- Act: Move the rods into our out of the chamber
PID controllers aren’t typically explained like this. Like I warned, I’m oversimplifying a lot. Normally, the focus is on integrals & derivatives; the “plan” step often directly computes how much it needs to change an actuator. The lesson you can carry from this is that even here, in AI agents, small incremental changes are beneficial to system stability (don’t fill the context with garbage).
There’s a whole lot that goes into PID controllers, many PhD’s have been minted for researching them. But the fundamentals apply widely to any long-running system that you want to keep stable.
Ya know, like agents.
Multi-Agents
An agent, in ‘25 parlance, is when you give an LLM a set of tools, a task, and loop it until it completes the task. (Yes, that does look a lot like a PID controller, more on that later).
A multi-agent is multiple agents working together in tandem to solve a problem.
In practice, which is the target of my scorn, a multi-agent is when you assign each agent a different role and then create complex workflows between them, often static. And then when you discover that the problem is more difficult than you thought, you add more agents and make the workflows more detailed and complex.
Multi-Agents Don’t Work
Why? Because they scale by adding complexity.
Here I should go on a tangent about the bitter lesson, an essay by Rich Sutton. It was addressed to AI researchers, and the gist is that when it comes down to scaling by (humans) thinking harder vs by computing more, the latter is always the better choice. His evidence is history, and the principle has held remarkably well over the years since it was written.
As I said, multi-agent systems tend to scale to harder problems by adding more agents and increasing the complexity of the workflows.
This goes against every bone in my engineering body. Complexity compounds your problems. Why would increasing the complexity solve anything? (tbf countless engineering teams over the years have tried anyway).
The correct way to scale is to make any one of your PID controller components better.
Plan better. Act more precisely. Verify more comprehensively.
Deep Research: A Multi-Agent Success Story
Han Xiao of Jina.ai wrote an absolutely fantastic article about the DeepSearch & DeepResearch copycats and how to implement one yourself. In it was this diagram:
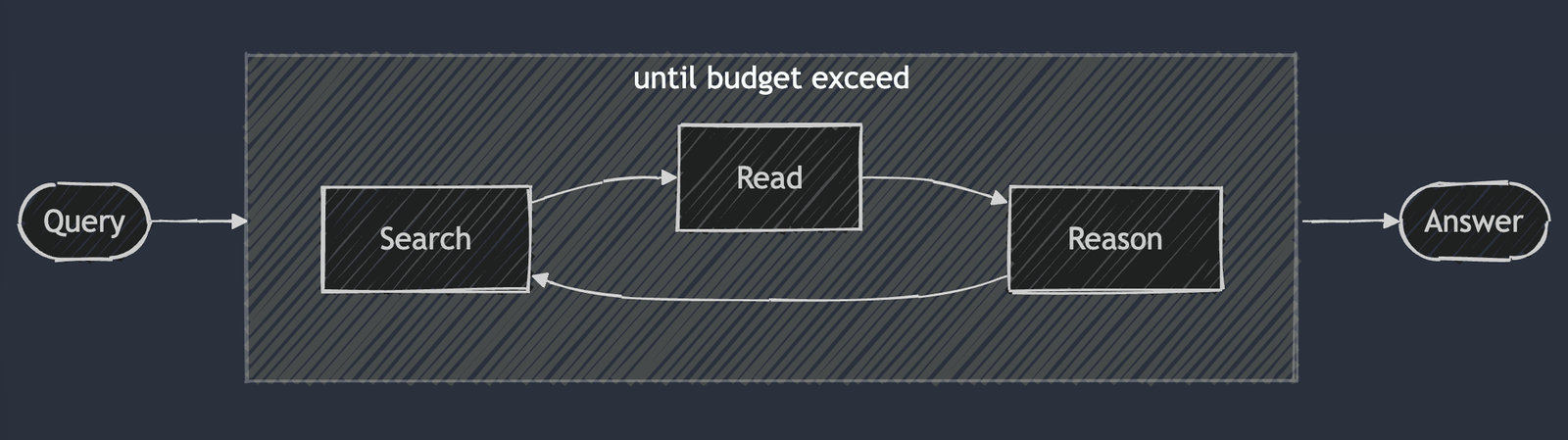
Dear lord is that a PID controller? I think it is..
- Reason = Plan
- Search = Act
- Read = Verify
The article also makes asks a crucial question:
But why did this shift happen now, when Deep(Re)Search remained relatively undervalued throughout 2024?
To which they conclude:
We believe the real turning point came with OpenAI’s o1-preview release in September 2024, … which enables models to perform more extensive internal deliberations, such as evaluating multiple potential answers, conducting deeper planning, and engaging in self-reflection before arriving at a final response.
In other words, DeepResearch knockoffs didn’t take off until reasoning models improved the capacity for planning
Cursor Agent
My sense of Cursor Agent, based only on using it, is that it also follows a similar PID controller pattern. Responses clearly (to me) seem to follow a Plan->Act->Verify flow, but the Act phase is more complex, with more tools:
- Search code
- Read file
- [Re]write file
- Run command
As far as I can tell, the “lint” feature didn’t used to exist. And in the release where they added the “lint” feature, the stability of the agents improved dramatically.
Also, releases in which they’ve improved Search functionality all seemed to have vastly improved the agent’s ability to achieve a goal.
Multi-Agent => Smarter Single-Agent
Claude Code, as far as I can tell, is not a multi-agent system. It still seems to perform each Plan, Act, Verify step, but each of the steps become fused into a single agent’s responsibility. And that agent just runs in a loop with tools.
I believe that the natural next step after a multi-agent PID system is to streamline it into a single agent system.
The reason should be intuitive, it’s less complexity. If the LLM is smart enough to handle the simpler architecture, then improving the agent is a matter of compute. Training an even smarter model (computing more) yields better agent performance. It’s the bitter lesson again.
How To Improve Agents
The answer is simple, though likely not easy:
- Plan — Make the model better. Improved reasoning is a time-tested strategy.
- Act — Improve how actions are performed. Better search, better code-writing, etc.
- Verify — Improve your verification techniques. Add static analysis, unit tests, etc.
If your answer is to add more agents or create more complex workflows, you will not find yourself with a better agent system.
Final Thoughts
I do think there’s a world where we have true multi-agent systems, where a group of agents are dispatched to collaboratively solve a problem.
However, in that case the scaling dimension is work to be done. You create a team of agents when there’s too much work for a single agent to complete. Yes, the agents split responsibilities, but that’s an implementation detail toward scaling out meet the needs of the larger amount of work.
Note: There’s probably other design patterns. One that will likely be proven out soon is the “load balancer” pattern, where a team of agents all do work in parallel and then a coordinator/load balancer/merger agent combines the team’s work. For example, the team might be coding agents, all tackling different Github issues, and the coordinator agent is doing nothing but merging code and assigning tasks.
In the mean time, using multi-agents to solve increasingly complex problems is a dead end. Stop doing it.