Agents are Systems Software

Agents are hard to build. And when they’re done well, they’re highly generic and extendable. They’re systems, like web browsers or database engines.
I know! There’s frameworks to build agents. But those are mostly a lie, and they generally skip out on the hardest parts.
Caveat: If by agent you mean a script that uses an LLM, then fine keep writing agents. That’s great, keep going.
Web browsers & Databases
Two pieces of software that everyone uses, everyone builds on, and no one wants to own.
How does that work? They’re scriptable. JS, CSS & HTML for the browser, SQL for the database. Both are systems software. Heavily customizable, heavily reusable, and extremely battle tested. It’s software so solid that you build on it rather than building it.
Systems software.
There was a time when every company thought they needed to own their own database engine. There’s large systems that built on frameworks like MUMPS & 4GL to create custom database engines. Basically, the business software became so tightly coupled to the underlying database that the database engine was effectively custom built.
SQL ended up winning, because it’s scriptable and heavily customizable.
Web browsers had a similar arc. Nexus, Lynx & Mosaic all were owned by universities & startups that thought they needed a custom experience. Nowadays there’s Chrome and…actually, I think that’s it.
When everyone had their own database and web browser, all the software was super shaky and broken most of the time. Part of our evolution into high scale and reliable software was embracing that we didn’t need to customize as much as we thought.
So you want to make an agent…
There’s a lot of agent approaches, but the products that actually work (Claude Code, codex, Manus, etc.) all follow the Deep Agents pattern (oh, I hate that name).
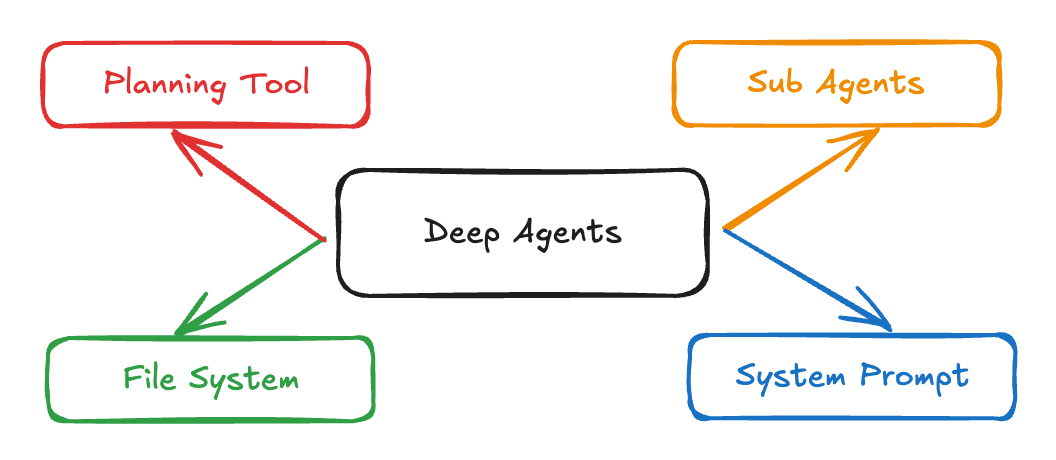
Go ahead and read that blog for details, it’s interesting. Back when it came out I jammed out an implementation, including an isolated filesystem and subagents. It worked, but wow. That was a lot. I came away deciding that I don’t want to own that code.
Why? Because none of it is specific to my company’s business. We don’t need to build a deep agent, we just need to use one. It’s a ton of work, but it doesn’t give us a competitive advantage.
MCP clients are hard
It’s not hard to stick to the spec, it’s just hard to get them to perform well and be secure. MCP is biased toward making servers ridiculously easy to implement. Clients are a lot harder.
- Error handling — servers just throw errors, clients have to figure out what to do with them. Retry? Let the LLM figure it out? Break?
- Resources — Where do they go in the prompt? When? Do you invalidate the cache? These things aren’t in the spec.
- Tools — What if the server mutates the list of tools, does that jack up the prompt prefix caching?
- Permission — All this requires UI, and none of the MCP libraries are going to help here
- Sampling — heh, gosh i just got a headache
It just keeps going
- Prompt caching — how do you handle it?
- Provider-specific LLM APIs — e.g. Claude has context garbage collection, OpenAI has personalities
- Agent-to-Agent interaction — Even if you’re getting this for free from a framework, does it tie into an event loop? Do the agents run in parallel? Does your agent have visibility into the task statuses of subagents? deeper subagents?
- Sandboxing
- Security
How long should I keep going for?
The LangChain vision
The vibe I get from the LinkedIn influencers is that every company is going to have 500 different agents, and they’ll all attach and communicate through this huge agentic web.
When has that worked? Like ever, in the history of computing. Once the number of implementations grows, each individual one gets shaky af and they never inter-communicate well. It’s just how things work. Pretty sure there’s an internet law for it somewhere. Maybe an XKCD.
We can’t have thousands of agent implementations.
Claude Code & Codex are general agents
Yes, I realize they’ve been sold as being for coding. And they’re really good at that. But you need access to the filesystem to have powerful agents.
Files give the agent a way to manage it’s own memory. It can search through files to find information. Or it can write notes to itself and remember things. An ad-hoc filesystem is crucial for a powerful agent, but the only agents that provide that are coding agents.
But also, I have some friends who use Claude Code but not for writing code. They’re not software engineers. They use it for marketing, sales, whatever. These are general agents. Anthropic has gotten smart and is moving Claude Code into the cloud and dropping the “Code” part of the name. Same thing though.
They’re customizable
My lightbulb went off when Anthropic announced Claude Skills.
Anything you want an agent to do, you can do it through Claude Code and some combination of prompts, skills, MCP servers, and maybe scripts (if that’s your thing). Same deal with Codex.
The way you build 500 agents per company is to heavily customize out-of-the-box general agents like Claude Code and Codex. Give them prompts, MCP servers, connect them together, etc. Don’t build agents from scratch, that’s crazy.
Another lightbulb moment was when I talked to an enterprise about how to implement A2A. It was a great session, but let me tell ya. It’s not gonna happen unless it amounts to attaching one application to another via a standard protocol.
Agents are Systems Software
Systems software is hard to build. That’s fine. Good even. Because a whole lot of people can benefit from that work. You should!