MCP Colors: Systematically deal with prompt injection risk

Prompt injection is annoying enough that most (all??) apps so far are mostly just ignoring that it exists and hoping a solution will come along before their customer base grows enough to actually care about security. There are answers!
But first! Breathe deeply and repeat after me: “it’s impossible to reliably detect prompt injection attacks, and it probably always will be”. Breathe deeply again, and accept this. Good, now we’re ready to move on.
How do we make a secure agent?
Simon Wilison has been the leading voice here, with his initial Lethal Trifecta and recently aggregating some papers that build on it. In these ideas, there’s a Venn diagram with 3 circles:
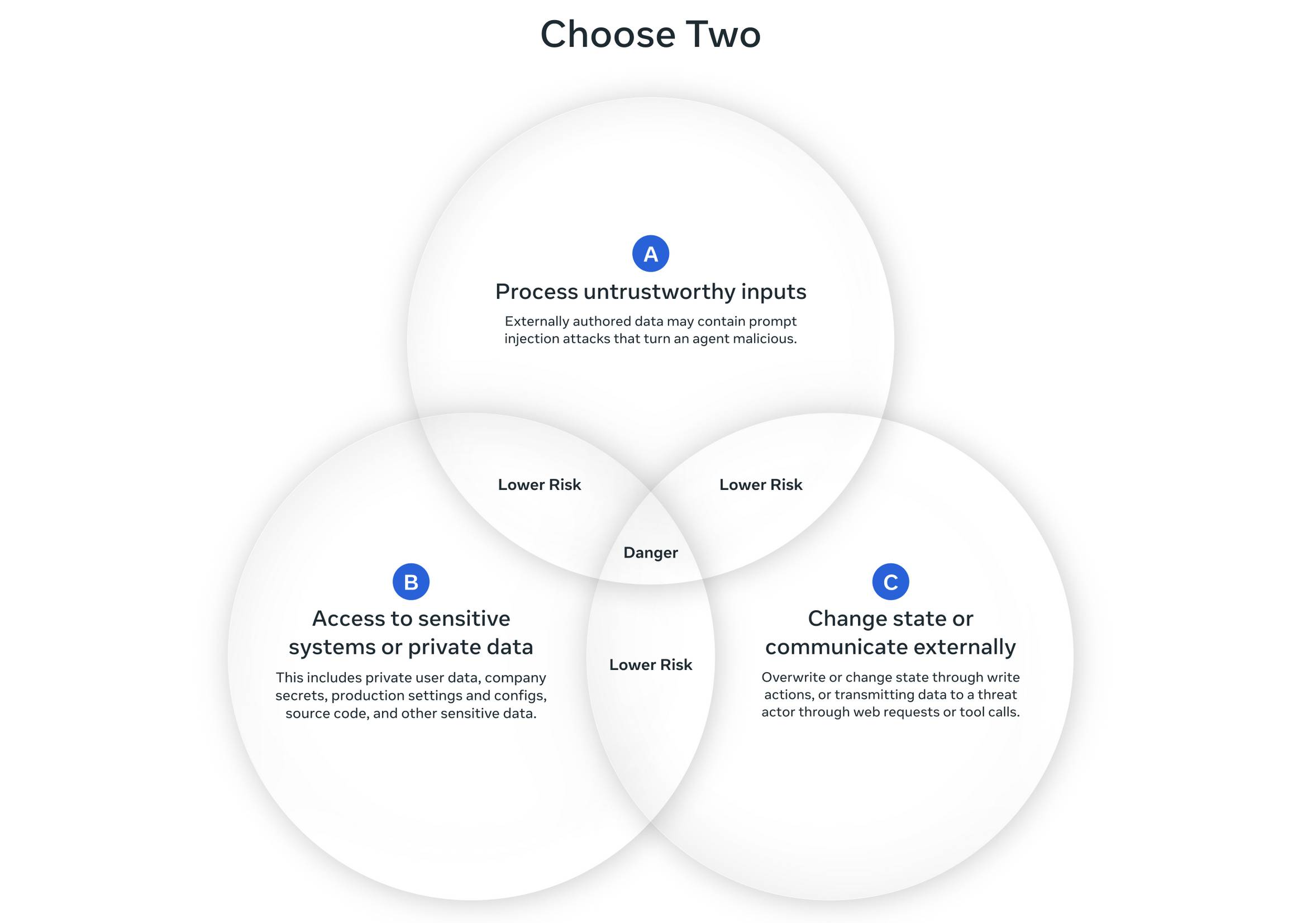
The more recent paper broadened Simon’s “Ability to communicate externally” (i.e. exfiltrate) to include anything that changes state.
MCP Colors 101
In my work, I’ve decided that Simon’s diagram can be simplified to 2 circles, because I always deal with private data. I rephrase those as “colors” that I can slap on MCP tools & label data inputs:
| Untrusted content (red) | Critical actions (blue) |
| Google search MCP tool | Delete email |
| Initial input includes .pdf from a prospect | Change a user's permissions |
| Tool searches CPT code database acquired from internet | Send email to CEO |
Another change I’ve made is calling it “Critical Ations”. Simon initially limited it to exfiltration, and his recent post expands it to “changes state”. But it’s not always clear. For example, that last one, sending an email to a CEO is clearly not exfiltration (the CEO is certainly authorized to see the information), and it’s also not really changing state, it’s just sending an email. But it could get super embarassing if it sent the wrong email, or too many.
It’s something you want to be reeeally careful about; a critical action.
Labeling Colors
It’s simple: an agent can have red or blue but not both.
The Chore: Go label every data input, and every tool (especially MCP tools).
For MCP tools & resources, you can use the _meta object to keep track of the color.
The agent can decide at runtime (or earlier) if it’s gotten into an unsafe state.
Personally, I like to automate. I needed to label ~200 tools, so I put them in a spreadsheet and used an LLM to label them. That way, I could focus on being precise and clear about my criteria for what constitutes “red”, “blue” or “neither”. That way I ended up with an artifact that scales beyond my initial set of tools.
Why do this?
There’s a lot beyond just prompt injection.
Another big problem with MCP is how big it is. Like, the entire point of it is that you don’t have to know what tools you want to use at runtime. You’ll figure that out later.
But from a security perspective that’s nuts. You’re saying you want to release this AI agent thing, and you’re not sure how you want to use it?? Uh no.
Even if you manage to clearly articulate how it’ll be used, now you’ve got O(n^m) different combinations
of different tools to do penetration testing against. That’s certainly job security for pen testers,
but I don’t think most companies would sign up for that.
Focused conversations
When reasoning about the safety of an agent, you only need to consider a single tool at a time. Is it actually red? Are there times where it’s not?
De-coloring
Can you take a tool that’s colored “red” and remove the color? If you could, that would let you put red and blue tools in the same agent.
This seems basically the same as web form validation. It should be possible to do this with unstructured input as well. Like, I think most people would agree that having 10 human beings review a piece of text is enough to “validate” it. What about 1? Maybe there’s cases where LLM-as-a-judge is enough?
Color levels
A collegue suggested a modification: Allow levels 1-5 of each color and set thresholds for blue & red. This is interesting because it allows you to say, “I trust this document more now, maybe not completely, but more than I did”. Partial trust gives us even more options for de-coloring.
Also, it decouples the initial color labels from user preferences & risk tolerance. It lets some users take risks when they think it matters. It also provides a high level view of risks you’re taking. You don’t need to understand the ins & outs of how an agent works. You can control (or just quantify) the risks on a high level that also gives you fine-grained control.
General agents
On a more optimistic note, this feels like a potential path to very general agents running securely. Agents that discover new tools & new agents to interact with. At the moment that all feels technically possible, maybe, but a complete security nightmare. This might actually be a decent path toward that.
Conclusion
Simon wanted me to write it up. I did. I think it’s a good idea, but I’d love more feedback.
Something not voiced explicitly — yeah, this means you have to actually think about what’s going into your tools. Sure, this helps scope the conversation so it’s more tenable. But there’s no free lunch. If you want security, you’re going to have to think a bit about what your threat model is.