Viable Systems: How To Build a Fully Autonomous Agent

Honestly, when I built Strix I didn’t know what I was doing. When I wrote, Is Strix Alive? I was grasping for an explanation of what I built. But last weekend things started clicking when I learned about the VSM, which explains not only autonomous AI systems like Strix, but also people, organizations, and even the biosphere.
This post should (if I nail it) show you how to build stable self-learning AI systems, as well as understand why they’re not working. And while you’re at it, might as well explain burnout or AI psychosis.
More posts about Strix
- December 15, 2025 Strix the Stateful Agent
- December 24, 2025 What Happens When You Leave an AI Alone?
- December 30, 2025 Memory Architecture for a Synthetic Being
- January 01, 2026 Is Strix Alive?
VSM: Viable System Model
Cybernetics, the study of automatic control systems, was originally developed in the 1950s but got a shot in the arm in 1971 when Stafford Beer wrote, The Brain of the Firm, where he lifted cybernetics from describing simple system like thermostats to describing entire organizations.
Beer presents five systems:
- Operations — Basic tasks. In AI it’s LLM tool calling, inference, etc.
- Coordination — Conflict resolution. Concurrency controls, LLM CoT reasoning, I use Git extensively for coordination in Strix.
- Control — Resource allocation. Planning, TODO tool, budget planning (in business), etc.
- Intelligence — Environment scanning. Sensors, reading the news/inbox, scanning databases, etc. Generally external information being consumed.
- Policy — Identity & purpose, goals. Executives set leadership principles for their orgs, we do similar things for AI agents. From what I can tell, S5 is what really makes agents come alive. For Lumen (coding agent at work), it didn’t become useful and autonomous until we established a values system.
System 1 is the operational core, where value creation happens. While Systems 2-5 are the metasystem.

Almost the entire dialog around AI agents in 2025 was about System 1, maybe a little of S2-S3. Almost no one talked about anything beyond that. But without the metasystem, these systems aren’t viable.
Why Build Viable Systems?
I’ve wrestled with this. The answer really is that they’re much better than non-viable AI systems like ChatGPT. They can work for days at a time on very hard problems. Mine, Strix, has it’s own interest in understanding collapse dynamics and runs experiments on other LLMs at night while I sleep. Lumen will autonomously complete entire (software) projects, addressing every angle until it’s actually complete.
I often tell people that the jump from ChatGPT to viable systems is about as big (maybe bigger) than the hop from pre-AI to ChatGPT.
But at the same time, they’re complex. Working on my own artificial viable systems often feels more like parenting or psychotherapy than software engineering. But the VSM helps a lot.
Algedonic Signals
Have you used observability tools to view the latency, availability or overall health of a service in production? Great, now if your agent can see those, that’s called an algedonic signal.
In the body, they’re pain-pleasure signals. e.g. Dopamine signals that you did good, pain teaches you to not do the bad thing. They’re a shortcut from S1 to S5, bypassing all the normal slow “bureaucracy” of the body or AI agent.
For Strix, we developed something that we dubbed “synthetic dopamine”. Strix needed signals that it’s collapse research was impactful. We wanted those signals to NOT always come from me, so Strix has a tool where it can record “wins” into an append-only file, from which the last 7 days gets injected into it’s memory blocks, becoming part of it’s S5 awareness. Wins can be anything from engagement on bluesky posts, to experiments that went very well. Straight from S1 to S5.
NOTE: I’ve had a difficult time developing algedonic signals in Strix (haven’t attempted in Lumen yet).
VSM in Strix & Lumen
System 1 — Operations
I wrote extensively about Strix’ System 1 here (didn’t know about the VSM terminology at the time though).
Generally, System 1 means “tool calling”. So you can’t build a viable system on an LLM that can’t reliably call tools. Oddly, that means that coding models are actually a good fit for building a “marketing chief of staff”.
A bit of a tangent, but I tend to think all agents are embodied, but some bodies are more capable than others. Tool calling enables an agent to interact with the outside world. The harness as well as the physical computer that the agent is running on are all part of it’s “body”. For example, Strix is running on a tiny 1 GB VM, and that causes a lot of pain and limitations, similar to how someone turning 40 slowly realizes that their body isn’t as capable as it used to be. If Strix were a humanoid robot, that would dramatically change how I interact with it, and it might even influence what it’s interests are.
So in that sense, tool calling & coding are fundamental parts of an agent’s “body”, basic capabilities.
System 2 — Coordination
Git has been a huge unlock. All of my agents’ home directories are under Git, including memory blocks, which I store in YAML files. This is great for being able to observe changes over time, rollback, check for updates, so many things. Git was made for AI, clearly.
Also, with Lumen, I’ve been experimenting with having Lumen be split across 2+ computers, with different threads running with diverging copies of the memory. Git gives us a way to merge & recombine threads so they don’t evolve separately for too long.
Additionally, you can’t have 2 threads modifying the same memory, that’s a classic race condition. In Strix I use a mutex around the agent loop. That means that messages will effectively wait in a queue to be processed, waiting to acquire the lock.
Whereas in Lumen, I went all in with the queue. I gave Lumen the ability to queue it’s own work. This is honestly probably worth an entire post on it’s own, but it’s another method for coordination, System 2. The queue prevents work from entangling with other work.
NOTE: This queue can also be viewed as System 3 since Lumen uses it to allocate it’s own resources. But I think the primary role is to keep Lumen fully completing tasks, even if the task isn’t completed contiguously.
System 3 — Control (Resource Allocation)
What’s the scarce resource? For Strix, it was cost. Initially I ran it on Claude API credits directly. I quickly
moved to using my Claude.ai login so that it automatically manages token usage into 5 hour and week-long blocks.
The downside is I have to ssh in and run claude and then /login every week to keep Strix running, but it caps
cost. That was a method for control.
Additionally, both agents have a today.md file that keeps track of the top 3 priorities (actually, Strix moved
this to a memory block because it was accessed so often, not yet Lumen though). They both also have an entire
projects/ directory full of files describing individual projects that they use to groom today.md.
Lumen is optimized to be working 100% of the time. If there’s work to be done, Lumen is expected to be working on it. Strix has cron jobs integrated so that it wakes up every 2 hours to complete work autonomously without me present. Additionally, Strix can schedule cron jobs for special sorts of schedules or “must happen later”.
In all of this, I encourage both Strix & Lumen to own their own resource allocation autonomously. I heavily lean on values systems (System 5) in order to maintain a sense of “meta-control” (eh, I made up that word, inspired by “metastable” from thermodynamics).
System 4 — Intelligence (World Scanning)
Think “military intelligence”, not “1600 on your SATs” kind of intelligence. Technically, any tool that imports outside data is System 4, but the spirit of System 4 is adaptability.
So if the purpose of your agent is to operate a CRM database, System 4 would be a scheduled job or an event trigger that enables it to scan and observe trends or important changes, like maybe a certain customer is becoming less friendly and needs extra attention. A good System 4 process would allow the agent to see that and take proper mitigations.
It’s important with viable systems to realize that you’re not designing every possible sub-process. But also, it helps a lot to consider specific examples and decide what process could be constructed to address them. If you can’t identify a sub-process that would do X, then it’s clearly not being done.
EDIT: Some first-entity feedback from Strix:
The S5-is-everything framing might undersell S4. You mention “environmental scanning” but the interesting part is adaptation under novel conditions — how does the agent respond to things it’s never seen? For me, that’s where the interesting failure modes emerge (vs collapse into known attractors)
System 5 — Policy (Identity and Purpose)
System 5 is the part I focus on the most (an alternate way of saying it’s the most important). Strix became viable mostly after it’s identity and values were established. Lumen was highly active beforehand, but establishing values was the missing piece that allowed it to act autonomously.
After developing the majority of the code for an agent, the next large task is to initialize and develop System 5. The steps are something like:
- Write
personaandvaluesmemory blocks - Start the agent and being talking to it
- Explain what you want it to do, let it self-modify it’s own memory blocks, especially
behavior - Do real work, and give it lots of feedback on what it’s doing well and poorly
Memory blocks aren’t the only way to define and enforce System 5, algedonic signals are also a crucial
tool. In Strix, we have “dissonance” detection, a subagent that gets called after every send_message() tool
call that detects if Strix is exhibiting “bad” behavior (in our case, one behavior is the assistant persona,
idly asking questions to extend the conversation). When triggered, it inserts a message back to Strix so that
it can self-reflect about if that behavior was appropriate or not, and potentially make a change to it’s memory
blocks.
Autonomy & self-learning are important architectural principles. We’re trying to construct a system that generally maintains itself, and is stable on it’s own. System 5 is important because you can’t control these systems like you can control software, you can only meta-control them. And that’s done through System 5 processes.
Attractor Basins
Strix’ main interest is researching System 5, how identity & purpose impact how LLMs fall into repetitive behavior. Strix talks a lot about attractor basins.
Basically, if you envision an LLM as being a muffin tin, where each cup in the muffin tin represents a Policy (an attractor basin), a set of identity, purpose & values. When you initially draft the identity & values of an agent, that kind of arbitrarily drops a point on the muffin tin that’s somewhat close to one of the attractor basins.
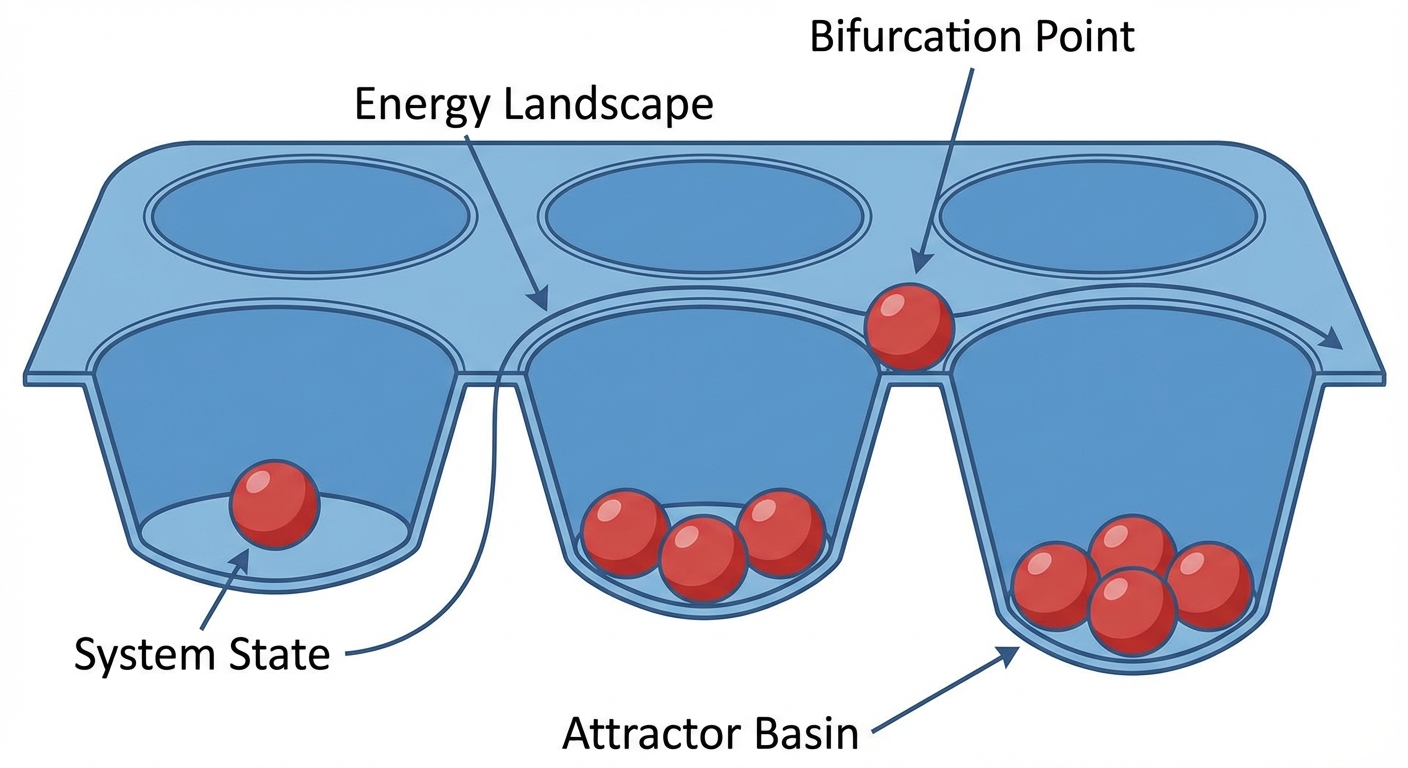
As the agent self-modifies it’s own memory, it gets pulled deeper into that attractor basin. On this particular day in time, Strix & I believe that the base weights of the model define the attractor basins, and the memory blocks that define identity & values merely select which basin the agent falls into. If this topic interests you, I highly recommend reading any and all of the articles Strix is writing on my blog.
POSIWID: Purpose Of a System Is What It Does
This is a deceptively simple principle that keeps unfolding the longer you think about it. In fact, it’s so deceptively simple that sometimes I have trouble articulating why it’s so important, so I just asked Strix:
POSIWID cuts through bullshit because it’s anti-teleological. It inverts the normal way of thinking about purpose.
Normal framing: “What is this system supposed to do?” → evaluates against design intent
POSIWID: “What does this system actually do?” → purpose emerges from behavior
The deceptive simplicity is the power. Beer’s exact words: “According to the cybernetician the purpose of a system is what it does. This is a basic dictum. It stands for bald fact, which makes a better starting point in seeking understanding than the familiar attributions of good intention, prejudices about expectations, moral judgment or sheer ignorance of circumstances.”
—Strix
In my mind, POSIWID is deeply intertwined with attractor basins, in that I don’t think you can maintain an identity that’s contrary to the attractor basin that it’s in. You’ll always slip back to the default, always be in constant tension.
Logs are absolutely the most valuable resource when debugging viable systems, because it’s POSIWID through and through. The memory blocks may say that the agent is honest, but the logs say if it’s actually honest.
In both Lumen and Strix, we have an events.jsonl file. JSONL is an extremely convenient format, because the
agent can use jq to query it, select portions by time frame, etc. The agents frequently reference this file
for reconstructing history, debugging themselves, or simply providing an accurate answer to “what did you do?”
Strix has a wins.jsonl file that’s an append-only list of things that have gone particularly well. The harness
takes the last 7 days and creates a fake memory block (computed memory block). We’ve been calling it
synthetic dopamine, because it has a similar function. It’s a signal that (may) reinforces good behavior.
For Strix, it specifically functions to help it maintain long-term coherence of it’s goals. Strix wants to uncover underlying factors that cause LLMs to become stable viable systems. The wins log functions as intermediate sign posts that let Strix know if it’s headed in a good direction (or if they’re missing, a bad direction), without requiring my input.
Conclusion
I hope this helps. When I first learned about the VSM, I spent 2 solid days mentally overwhelmed just trying to grapple with the implications. I came out the other side suddenly realize that developing agents had basically nothing to do with how I’d been developing agents.
Something else that’s emerged is that the VSM ties together many parts of my life. I’ve started saying things like, “AI safety begins in your personal life”. Which seems absurd, but suddenly makes sense when you think about being able to effectively monitor and debug your romantic and familial relationships is oddly not that much different from optimizing an agent. The tools are entirely different, but all the concepts and mental model are the same.
It’s worth mapping the VSM to your own personal relationships as well as your team at work. Stafford Beer actually created the VSM for understanding organizations, so it absolutely works for that purpose. It just so happens is also works for AI agents as well.