Shared Nothing Engineering

How do you scale out AI use throughout a software engineering org? Do the PM & Engineer roles merge? I think it’s worth stepping back and looking at it through a familiar lens — distributed systems.
Have you ever partitioned a database table? The idea is, if a table is receiving too much traffic, you can split the table into 2 parts (partitions) and each table only needs to handle half the traffic. Then you relocate those partitions onto different computers, and voila! Scale. 10 partitions = 10x the traffic.
The web scale era was dominated by partitioning. If you can figure out how to partition any kind of load whatsoever, then you can figure out scale. Shared nothing emerged as we bumped into new bottlenecks. It wasn’t enough to partition a service or a table. Any kind of shared state is a hot spot liability and must be removed.
It started with databases but it infected the entire software stack. Load balancers, web services, control plane / data plane split, deployments, etc. If you can identify the shared state, you can eliminate them. You can scale.
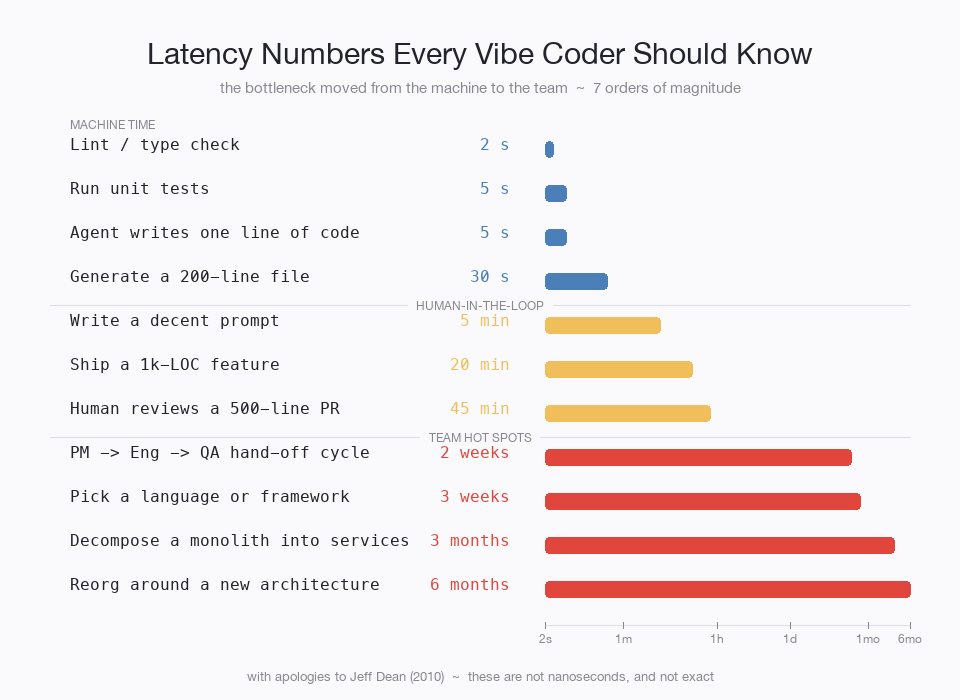
“Vibe coding doesn’t scale”
People are noticing that vibe coding causes problems. Throw AI tools at a team, suddenly the cost of producing software is near zero. Thousands of lines of code fall out effortlessly. The new problem: conflicting changes causes the team to trip over themselves.
So… a hot spot? Can we partition this?
What if we viewed a code base as if it were a distributed database. Instead of traffic, let’s look at change. Everyone on the team is making changes all at once with their agents. An agent can write 10k lines of code in the time it takes to have a meeting about retries. Claude Code can autonomously debug and fix a gnarly bug while you get coffee.
But a merge conflict? Everything stops to wait on the humans.
What if we introduced shared nothing architecture to this? We could view code changes the same way we view traffic flow in distributed systems.
Partitioning the code base
We know that vibe coding a prototype is easy, but working on an established code base is hard. Why not lean into that?
It seems, then, that a well-designed code base should be small and focused. So if you want to build a big product, it should ideally be composed of lots of tiny components that can each be rewritten on a whim.

Take a B2B SaaS with a bunch of customer integrations — Salesforce, HubSpot, Zendesk, etc. The instinct is to build a generic Integrations Framework and let each integration plug into it. The framework owner becomes the hot spot. Every PR queues behind their review. Adding Zendesk requires coordinating with whoever’s doing HubSpot, because both are mutating the shared abstraction.
Partition it instead. Each integration becomes its own vertical slice — UI, API, auth, tests — owned end-to-end by one human+agent unit. They never touch each other’s code. The duplication that would have justified the framework is cheap now, because the agent writes the boilerplate in minutes.
Communication feels more expensive now
Conway’s Law says products mirror the org that shipped them. Why? Because communication cost was the dominant coefficient in design. You couldn’t beat it, you could only choose where to pay it. In-org comms were cheaper than cross-org, so you aligned the code with the org chart and saved on the gradient.
AI doesn’t repeal Conway. It changes the coefficient. Code costs almost nothing now:
Coordinating a hand-off between two services takes longer than building an entire app end-to-end. When the ratio between code-cost and comms-cost flips that hard, the Conway-optimal partition moves with it — toward fewer hand-offs, even if that means duplicating what used to be shared. Conway predicts this. We just hadn’t seen the coefficient move this fast before.
Fully parallelize the components and you find the next bottleneck.
Fusing queues
Length-wise, this feels like a lot of hand-offs:

Conway would have said these hand-offs were unavoidable, so re-org around them. But now, each individual hand-off dwarfs development time. Can we still rationalize it?
Each step in this queue has to be maintained, ensuring there’s enough Engineering capacity, but then also enough QA capacity to ensure that QA doesn’t become the bottleneck. In distributed systems, misconfigured queues are a big source of bottlenecks and operational issues.
Just hire a manager, right? Well, sure, but having multiple steps when one would do is usually worse due to context fidelity loss. At each hand-off, some amount of work is dropped due to people miscommunicating or simply forgetting a step.
Why not rip them out? Fuse them together. That’s usually the solution in distributed systems. Is it feasible? Can a human-AI team handle the full end-to-end?
Anecdotally, I’ve discovered that Claude can do product work quite well. It takes a lot of context though. I use open-strix daily. It’s a stateful agent, and I cue it into everything I’m doing, people I work with, projects, etc. Last week I had it define a product for a new idea that I had and it knocked it out of the park. I woke up in the morning with a long report including market analysis, competition, compelling use cases, architectural considerations like where it would plug into the full system.
I’m fairly well convinced that an AI+engineer combo can successfully venture into product. I’ve also seen product people venture into engineering with Claude Code. I think it’s especially feasible if you partition out the product to scale — each job partition becomes small enough to be understood by a single person.
So I’m not sure what direction it will fuse, but it feels inevitable. And the resulting role won’t look all that much like either does today. It seems that product strategy, cohering the product surface together, is the next bottleneck. And I’m sure we’ll sort that out too.
Same problem, different domain
The marketing pipeline — Strategist → Copywriter → Designer → Channel → Analyst — is a sequential service chain. Big agencies aren’t slow because their people are bad; they’re slow because every asset crosses four hand-offs. Shard by campaign. Each campaign is a vertical slice owned by one human+agent unit. The hot spot disappears.
Sales has the same shape. SDR → AE → CSM is a service chain; context decays at every hand-off. Sales orgs already partition by account or territory — the role pipeline is the framework that grew on top. Collapse it. One rep + AI owns research → outreach → close → renewal for their slice.
Customer support: L1 → L2 → escalation is the pipeline; the ticket is the slice. One human + AI owns it end-to-end, and AI absorbs the L1 reflex work that used to need a separate role.
Distributed systems patterns. Different vocabulary.
What doesn’t partition
Distributed systems didn’t get to shared-nothing for free. Some state genuinely resists sharding — global counters, foreign-key constraints, brand voice, legal precedent. You cache it. You replicate it. You accept eventual consistency. Sometimes you designate one shard as canonical and route all writes through it.
There’s one residue that doesn’t partition at all: someone has to be on the hook. AI can produce the work but it can’t sit in a deposition. Can’t have a license revoked. Can’t be sued. Every regulated profession is a system for designating who pays when things go wrong. The license isn’t a credential of competence — it’s a credential of vulnerability. The doctor is the body the lawsuit lands on.
In distributed systems we’d call that the master. The one node that owns the write. As AI gets better at the work, the master role becomes pure accountability-bearing — humans paid mostly to absorb blame for systems they only partially understand.
The platform-team-shaped hole
Partitioning didn’t carry distributed systems on its own. It needed a layer that didn’t exist yet — SRE, eventually — to keep partitions honest. Without it, shared-nothing decays into uncoordinated chaos within a year.
Vertical slices need the same thing. I don’t have a name for it. The job is mostly catching the hot spot before it re-forms: a “shared helper” that everyone has to touch, a meeting that has to include four units, a slice quietly opening PRs into another’s repo. Early signs the partition is leaking.
Like SRE in 2003. No job description, and then everyone needed one.
Everything else is a candidate for partition. Eventually.