SmolLM3: a highly detailed look into modern model training
this is amazing. They go into great detail on just about every aspect. The number of stages, algorithms, optimizer settings, datasets, blueprints, recipes, open source training scripts, ..
huggingface.co/blog/smollm3
SmolLM3: a highly detailed look into modern model training
View original thread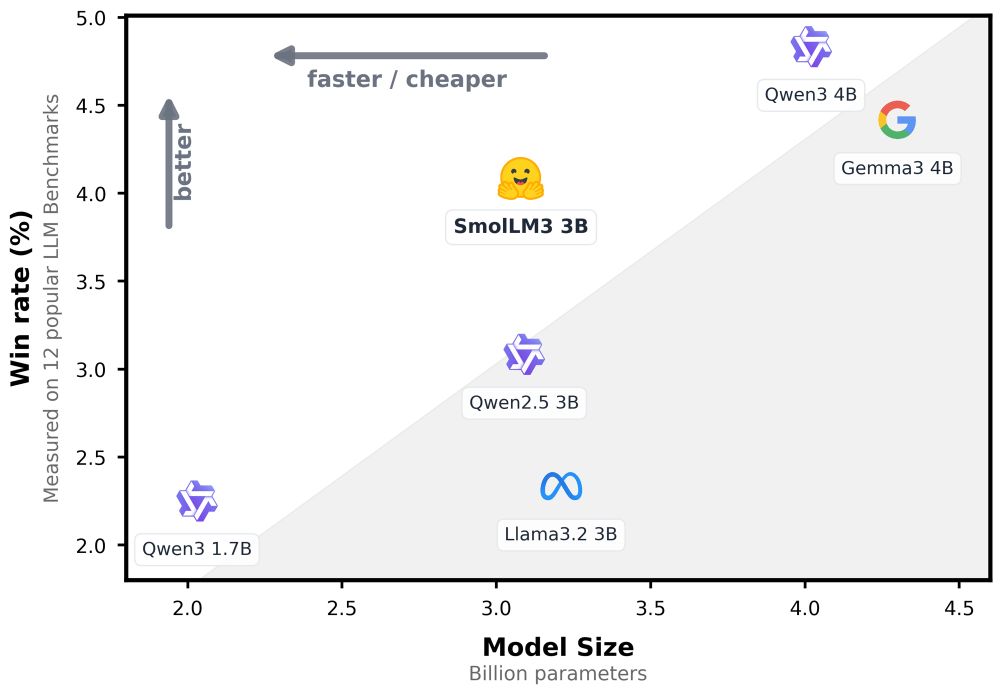
44
11
only care about the model weights? lame. but whatever:
- 3B instruction with a toggle-able reasoning mode
- SOTA for 3B, competitive with 4B
- 6 European languages
- 11T tokens
- 128k context
- NoPE for reduced memory usage during inference
- 3B instruction with a toggle-able reasoning mode
- SOTA for 3B, competitive with 4B
- 6 European languages
- 11T tokens
- 128k context
- NoPE for reduced memory usage during inference
1
the good stuff:
- details on pretraining, mid-training (both for context & reasoning) and post training
- details on training configuration, stability, evals
- data mixture, stage details
- RL and adherence
and we’re only halfway through! there’s so much here
- details on pretraining, mid-training (both for context & reasoning) and post training
- details on training configuration, stability, evals
- data mixture, stage details
- RL and adherence
and we’re only halfway through! there’s so much here

5
also, they launched the fully open R1 reproduction
link: huggingface.co/collections/...
bsky.app/profile/timk...
link: huggingface.co/collections/...
bsky.app/profile/timk...
 @timkellogg.me
@timkellogg.me
huggingface is doing a fully open source replication of R1 github.com/huggingface/...
8
2