openai researcher posts on X (not a blog or paper) about a model they have that can win the International Math Olympiad
you can’t verify anything he says, but he’s totally telling the truth
openai researcher posts on X (not a blog or paper) about a model they have th...
View original thread
29
2
tbf he did post the work for a few cherry picked problems
github.com/aw31/openai-...
i think the interesting part here (if true) is they used general RL, not math-specific RL, combined with test-time compute scaling
github.com/aw31/openai-...
i think the interesting part here (if true) is they used general RL, not math-specific RL, combined with test-time compute scaling
7
when they say there using test time scaling, they’re **really** using it

11
1
afaict they’re not using Lean or any other proof assistant at runtime, they say “without tools”
seems like a big hit to Gary Marcus’ belief in neurosymbolic reasoning
seems like a big hit to Gary Marcus’ belief in neurosymbolic reasoning
11
1
RL does better when you give partial credit, that was R1’s finding
this theory suggests they trained on extremely hard problems and created extremely tailored ways of giving partial credit, to incentivize good behavior, in a way that’s far too specific to scale
the innovation is scaling it
this theory suggests they trained on extremely hard problems and created extremely tailored ways of giving partial credit, to incentivize good behavior, in a way that’s far too specific to scale
the innovation is scaling it

8
1
i’m not sure if that’s true — Noam said they didn’t train only on Math problems
i suppose this really is a generic method though. if you can create highly detailed and customized rubrics for math, maybe you can do it for any domain
i suppose this really is a generic method though. if you can create highly detailed and customized rubrics for math, maybe you can do it for any domain
8
3 hours later
similar take, verifier is the innovation, but this one says there was basically no RL (instead of all RL)
verifiers are like that. they can be used for test time reasoning, or for RL training
verifiers are like that. they can be used for test time reasoning, or for RL training

1
9 hours later
interesting example of compression = intelligence
they must have fine tuned the IMO model to be extremely succinct
they must have fine tuned the IMO model to be extremely succinct
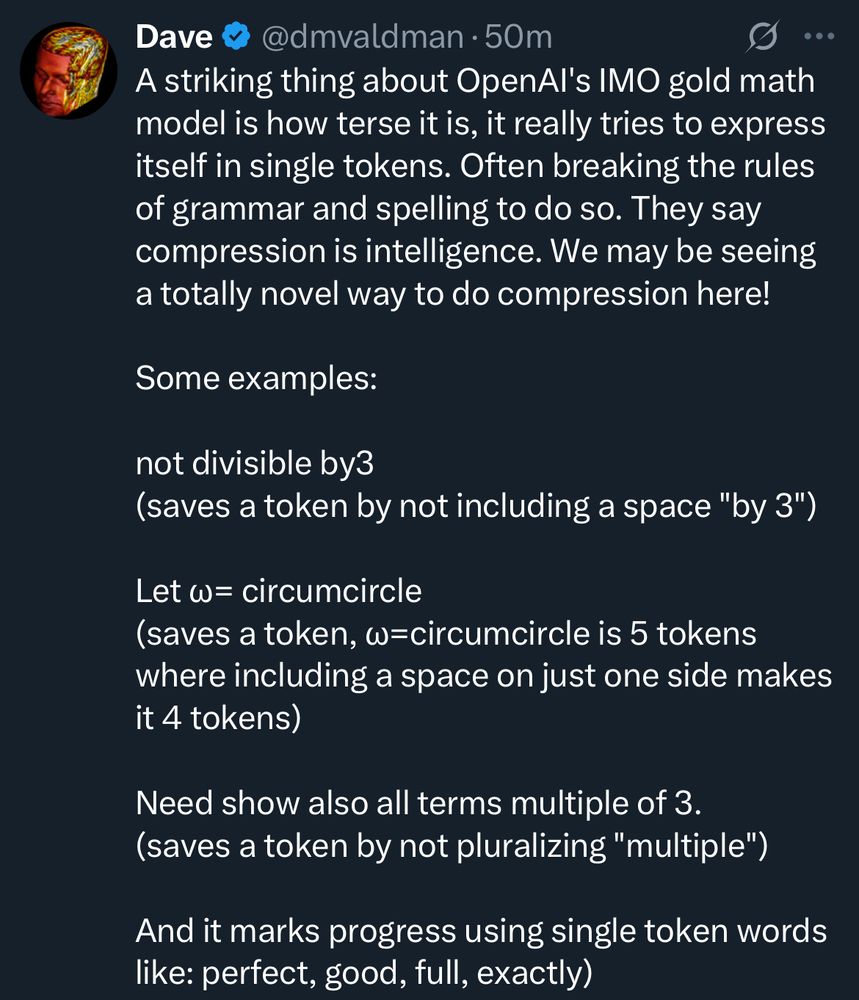
3