yesssss! a small update to Qwen3-30B-A3B
this has been one of my favorite local models, and now we get an even better version!
better instruction following, tool use & coding. Nice small MoE!
huggingface.co/Qwen/Qwen3-3...
yesssss! a small update to Qwen3-30B-A3B
View original thread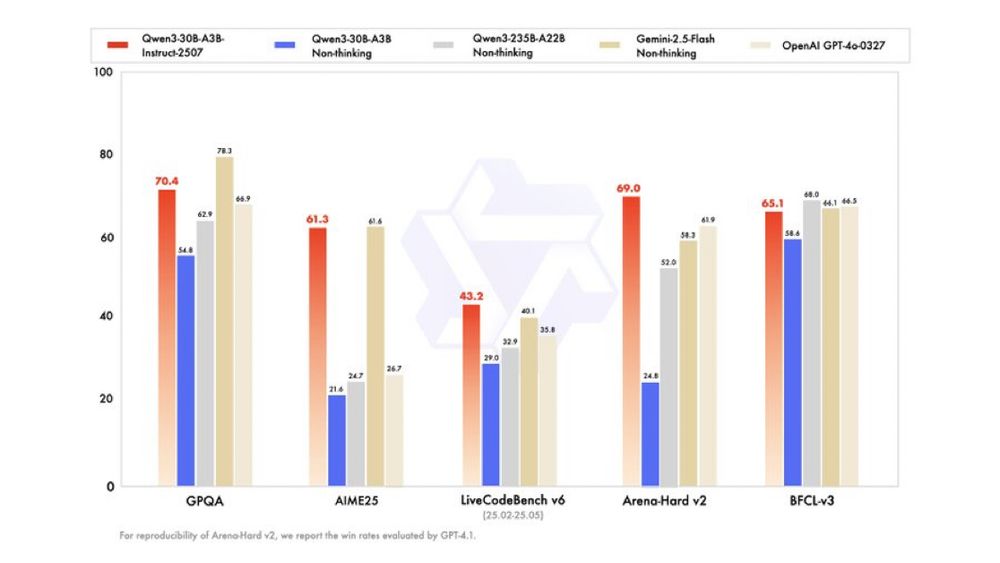
46
4
sadly, i have to kill off an existing model in order to load this one. which should go?

4
2 hours later
left: old checkpoint
right: new checkpoint
right: new checkpoint


3
me: "if you're flying over the desert in a canoe and your wheels fall off, how many pancakes does it take to cover a doghouse?"
qwen: "It takes exactly as many pancakes as the number of wheels you *wish* you had on your canoe."
i've never gotten that answer from an LLM before 🤯
qwen: "It takes exactly as many pancakes as the number of wheels you *wish* you had on your canoe."
i've never gotten that answer from an LLM before 🤯
12