XBai-o4: a new supermodel
* Open weights, apache 2
* 32B
* beats o3-mini
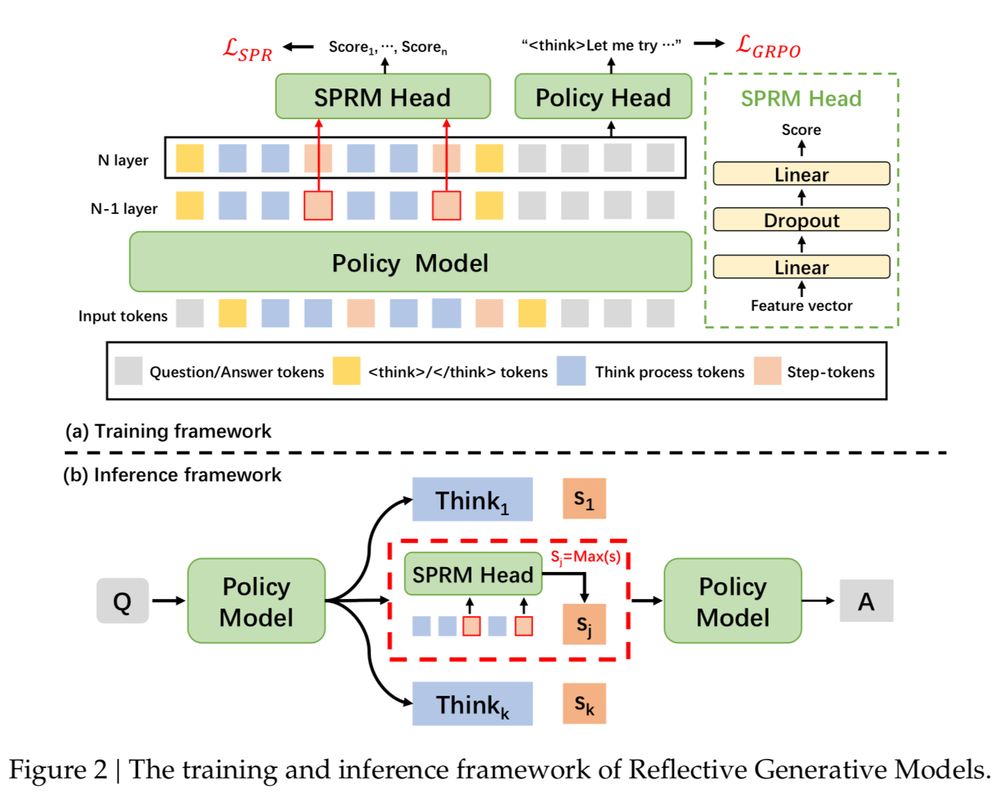
* for TTC they train an extra head as a reward model to do binary classification
hf: huggingface.co/MetaStoneTec...
paper: arxiv.org/abs/2507.01951
XBai-o4: a new supermodel
View original thread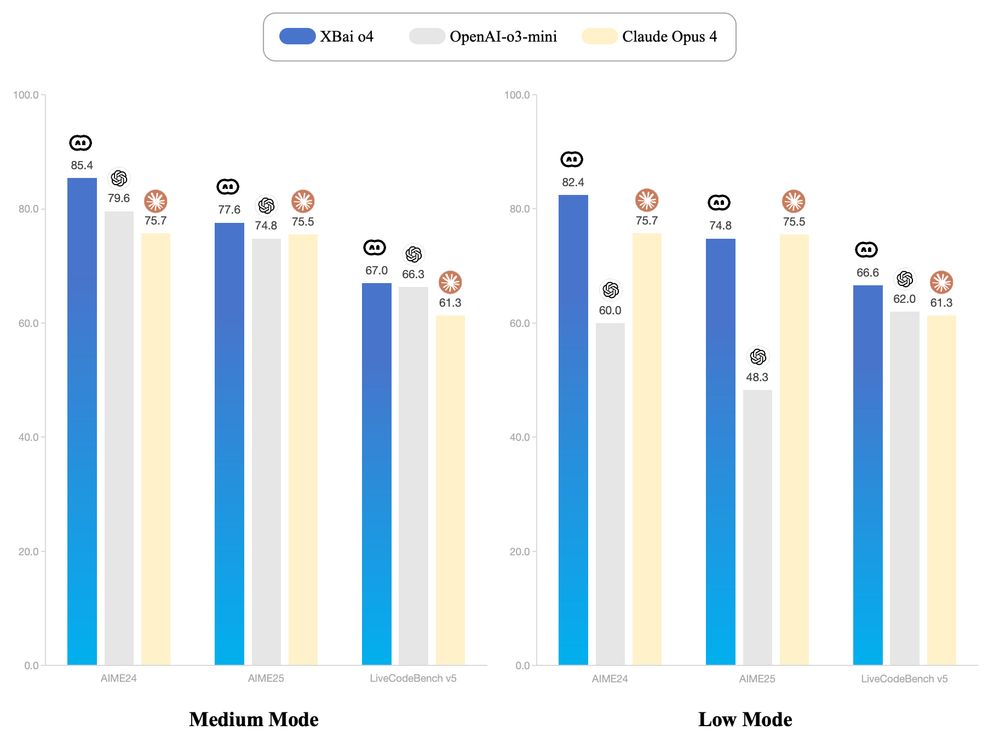
36
7
also: who????
7
it uses a Self-supervised Process Reward Model (SPRM) to grade several reasoning trajectories
the SPRM is a different model, but mostly not. Same base + 53M for the grading
the SPRM is a different model, but mostly not. Same base + 53M for the grading
9
1
it’s safe to say we’re long past Ollama
with Ollama, it’s gotta be represented as a single gguf execution graph. this double-uses the same weights Matryoshka-style to support as second model running at the same time
with Ollama, it’s gotta be represented as a single gguf execution graph. this double-uses the same weights Matryoshka-style to support as second model running at the same time
8
the vibe i get is that the OpenAI & DeepMind IMO Gold models also did similar tricks
is the SPRM the same model? sort of, i guess
is the SPRM the same model? sort of, i guess
7