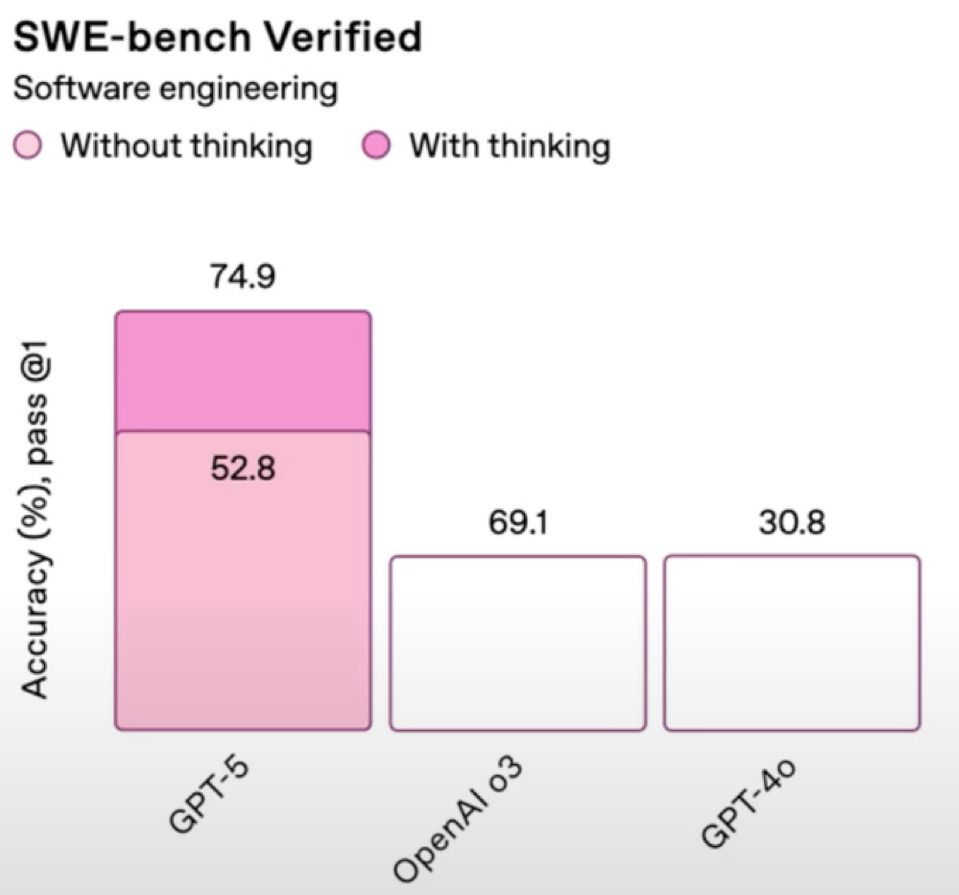
Bluesky Thread they corrected this already, but 😂 August 07, 2025 View original thread they corrected this already, but 😂 21 1 hour later really killing these charts today 8 1