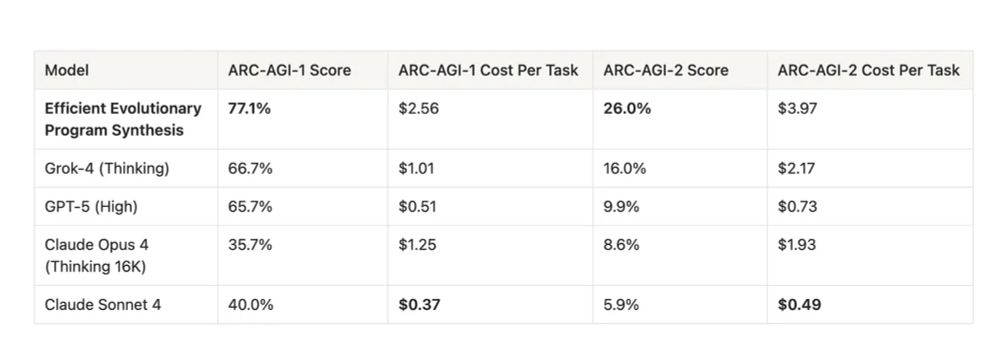
the top 2 ARC entries are by individuals
here, Eric Pang breaks down how he added memory to avoid recomputing learned lessons
ctpang.substack.com/p/arc-agi-2-...
the top 2 ARC entries are by individuals
View original thread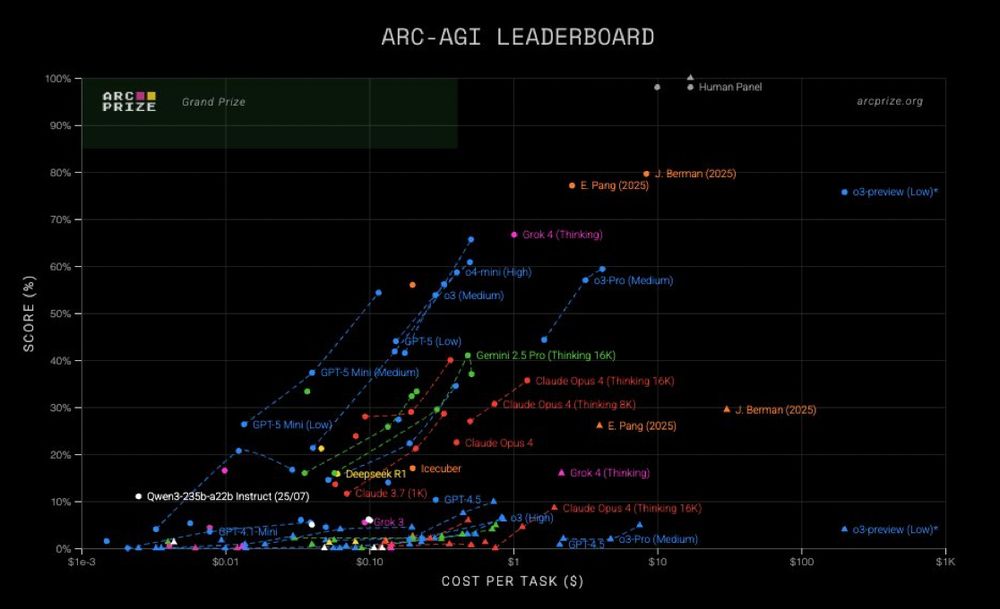
35
4
Eric tried several LLMs and went with the one that worked best, Grok 4 Thinking
4
Jeremy Berman has the top submission (but more expensive), also Grok 4. His write-up here
it works by spawning subagents to solve sub-problems in parallel
both of these are open source
jeremyberman.substack.com/p/how-i-got-...
it works by spawning subagents to solve sub-problems in parallel
both of these are open source
jeremyberman.substack.com/p/how-i-got-...
10
3 hours later
correction: Berman was a synthesis of Anthropic, Grok, OpenAI, DeepSeek & Gemini
4