RLP: Reinforcement Learning in Pre-Training
an NVIDIA paper explores using dense verifier-free RL in pretraining
this feels significant. Everything else I’ve been seeing is moving the other direction, do more in pre-training
dense rewards changes things
research.nvidia.com/labs/adlr/RLP/
RLP: Reinforcement Learning in Pre-Training
View original thread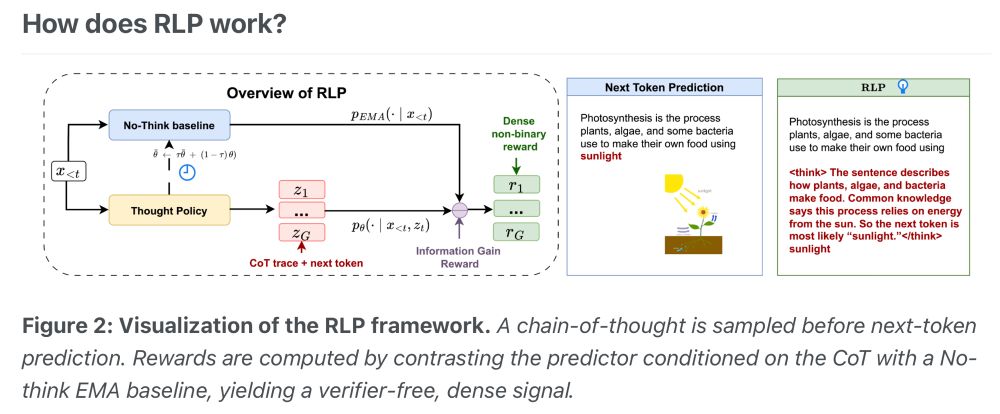
29
3
it works too. look at this
isolated impact of RTP
it also seems to hold and maybe even improve with increased model size
isolated impact of RTP
it also seems to hold and maybe even improve with increased model size
![The bar chart compares average accuracies between two setups: Base (light blue) and Base+RLP (dark green).
• Math:
• Base: 61
• Base+RLP: 65
• Science:
• Base: 35
• Base+RLP: 57
• Science Pass@1[4]:
• Base: 33
• Base+RLP: 61
• Overall:
• Base: 47
• Base+RLP: 63
Observation:
Across all categories (Math, Science, Science Pass@1[4], Overall), applying RLP significantly improves accuracy. The largest gain appears in Science Pass@1[4], jumping from 33 to 61. The smallest but still positive gain is in Math, from 61 to 65.](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:ckaz32jwl6t2cno6fmuw2nhn/bafkreih77ppfbjuifcqjdqi4jgmdgn6t2ottccqnmrqqptqjejtpo4775q@jpeg)
4
how it works?
it’s still next token prediction, but it’s allowed to break out of response-mode into thinking mode, just for a single token
dense rewards — again, still next token prediction, but it can get extra reward for CoT tokens that yield better predictive power
it’s still next token prediction, but it’s allowed to break out of response-mode into thinking mode, just for a single token
dense rewards — again, still next token prediction, but it can get extra reward for CoT tokens that yield better predictive power
4