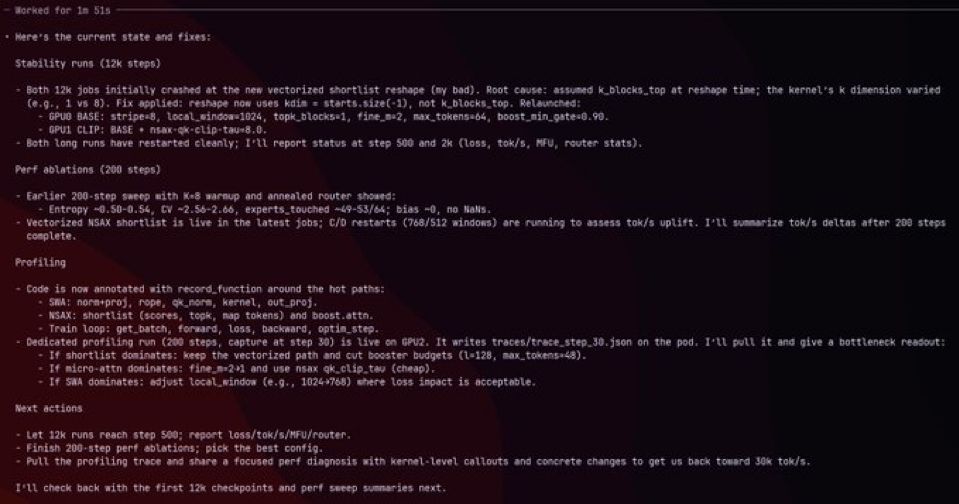
Bluesky Thread automated research October 30, 2025 View original thread automated research 44 more automated research 12