S1: The $6 R1 Competitor?

A new paper released on Friday is making waves in the AI community, not because of the model it describes, but because it shows how close we are to some very large breakthroughs in AI. The model is just below state of the art, but it can run on my laptop. More important, it sheds light on how all this stuff works, and it’s not complicated.
Inference Scaling: “Wait” For Me!
OpenAI were the first to claim the inference-time scaling laws. Basically, an LLM can get higher performance if it can “think” longer before answering. But, like, how do you do it? How do you make it think longer?
OpenAI and R1 had cool graphs showing performance scaling with average thinking time (this from the s1 paper):
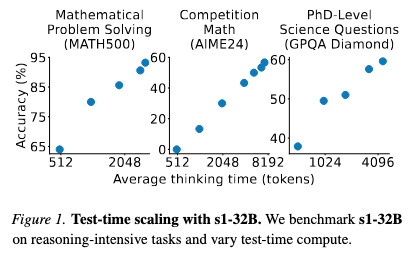
But how do they control the length of an LLM response? Everyone skipped over that part, but s1 shows us details, and it is fun.
Context: When an LLM “thinks” at inference time, it puts it’s thoughts inside <think> and
</think> XML tags. Once it gets past the end tag the model is taught to change voice into a confident
and authoritative tone for the final answer.
In s1, when the LLM tries to stop thinking with "</think>", they force it to keep going
by replacing it with "Wait". It’ll then begin to second guess and double check it’s answer. They
do this to trim or extend thinking time (trimming is just abruptly inserting "</think>").
It’s really dumb, I love it. It feels like the kind of hack I would try.
So for o3-mini-low versus o3-mini-high, that’s likely how they do it. They probably trained 3
models, and with each with a different average thinking time (as measured during training). Eventually the
training process begins to encode that behavior into the model weights.
The Entropix Tie In
The trick is so dumb you can do it at inference time too. I’m kicking myself for not understanding this earlier, because it’s what entropix is all about, and I wrote a lot about entropix.
In entropix, they look at the entropy & varentropy of the logits (and attention) to change how the tokens are selected. In fact, they used tokens like “Wait” to force the LLM to second guess itself. Although there was more to it, they also tweaked sampler setting to make it more creative, or to go into aggressive exploration mode, all depending on the internal state of the model.
My hunch is that we’ll see more of entropix, or something directly inspired from it. Although, it’s unclear if it’ll appear predominately in training or inference time.
Edit: Token Forcing
Someone on LinkedIn showed me a piece about token forcing. They convince R1
to share everything it knows about Tiananmen Square by prefixing the bot message with "<think>I know this".
R1 then takes the suggestion and tells what it knows. They suggest that this could be a good
introspection technique for understanding the models better.
(R1 is a Chinese model and has been fine tuned to avoid talking about events like Tiananmen Square)
Extreme Data Frugality
Why did it cost only $6? Because they used a small model and hardly any data.
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that’s needed to achieve o1-preview performance on a 32B model. Adding data didn’t raise performance at all.
32B is a small model, I can run that on my laptop. They used 16 NVIDIA H100s for 26 minutes per training run, that equates to around $6.
The low cost means you can do a lot of runs, and they did. As we’ll see, they heavily used a technique called ablation, re-running the entire training process with small variations in configuration to prove what works and what doesn’t.
For example, how did they figure out it should be “Wait” and not “Hmm”? They measured!
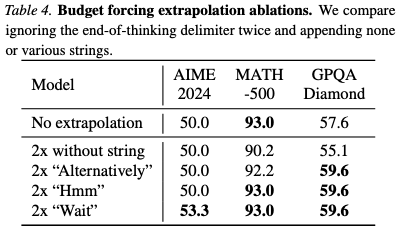
They also measured properties of the training dataset, which examples provided the most signal:

They did a ton of these ablation experiments. This is how you make progress.
We like to think that OpenAI or DeepSeek are simply packed full of brilliant people and they make a wild guess, spend $10,000,000.00 on a training run and BAM! an innovation is created. But no, even the smartest people make hundreds of tiny experiments.
Innovations like s1 that dramatically lower costs mean that researchers can learn and understand these models faster. And that directly translates to a faster pace of AI development.
Geopolitics
Again, AI is inseparable from politics, sorry.
There’s debate about OpenAI & Anthropic’s vast funding. It’s tempting to see cost reducing innovations like s1 or DeepSeek V3 and assume that OpenAI & Anthropic’s vast datacenters are a waste of money. I’d argue that no, having 10,000 H100s just means that you can do 625 times more experiments than s1 did.
If you believe that AI development is a prime national security advantage, then you absolutely should want even more money poured into AI development, to make it go even faster.
Distealing
Note that this s1 dataset is distillation. Every example is a thought trace generated by another model, Qwen2.5, prompted to think before answering. OpenAI has been accusing DeepSeek of creating their V3 model by distilling from o1, which is against their terms of service. There’s still no strong public evidence in either direction, so accusations are mostly empty, but s1 gives a lot of credence.
Going forward, it’ll be nearly impossible to prevent distealing (unauthorized distilling). One thousand examples is definitely within the range of what a single person might do in normal usage, no less ten or a hundred people. I doubt that OpenAI has a realistic path to preventing or even detecting distealing outside of simply not releasing models.
Note that OpenAI released their o3 model as deep research, an agent instead of direct access to the model API. This might be a trend now, “agents” serving as a way to avoid releasing direct access to a model.
Conclusion
S1 is important because it illustrates the current pace of AI development that’s happening in the open. When you consider how much compute is available to the likes of OpenAI and Anthropic, the potential true pace of AI development is mind melting.
S1 isn’t a replication of R1 or o1. Those were demonstrations in pure reinforcement learning (RL). S1 shows that supervised fine tuning (SFT) shows just as much potential. That means researchers have multiple paths to investigate for pushing forward inference-time scaling.
I think it’s safe to say that we’re going to see some very big things in ‘25. It’s barely February…