LLaDA: LLMs That Don't Gaslight You

A new AI architecture is challenging the status quo. LLaDA is a diffusion model that generates text. Normally diffusion models generate images or video (e.g. Stable Diffusion). By using diffusion for text, LLaDA addresses a lot of issues that LLMs are running into, like hallucinations and doom loops.
(Note: I pronounce it “yada”, the “LL” is a “y” sound like in Spanish, and it just seems appropriate for a language model, yada yada yada…)
LLMs write one word after the other in sequence. In LLaDA, on the other hand, words appear randomly. Existing words can also be edited or deleted before the generation terminates.
Example: “Explain what artificial intelligence is”
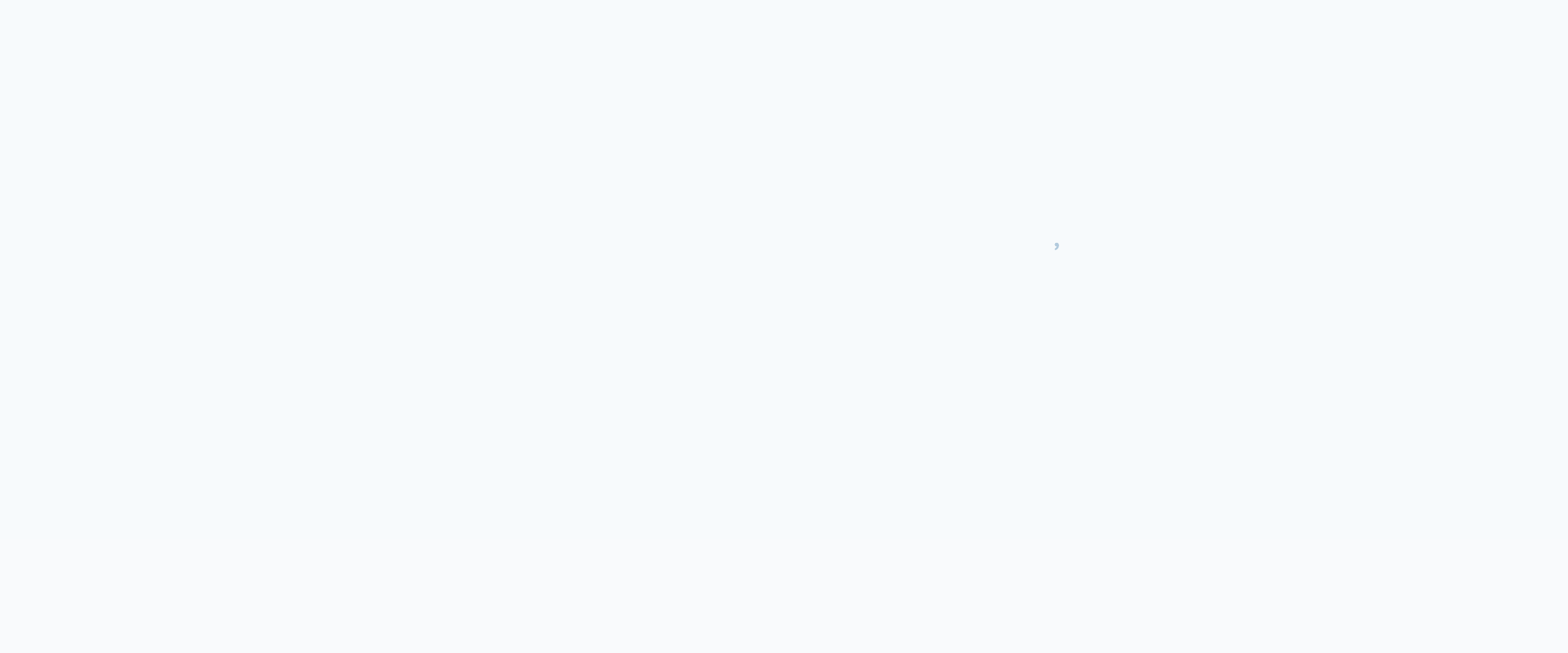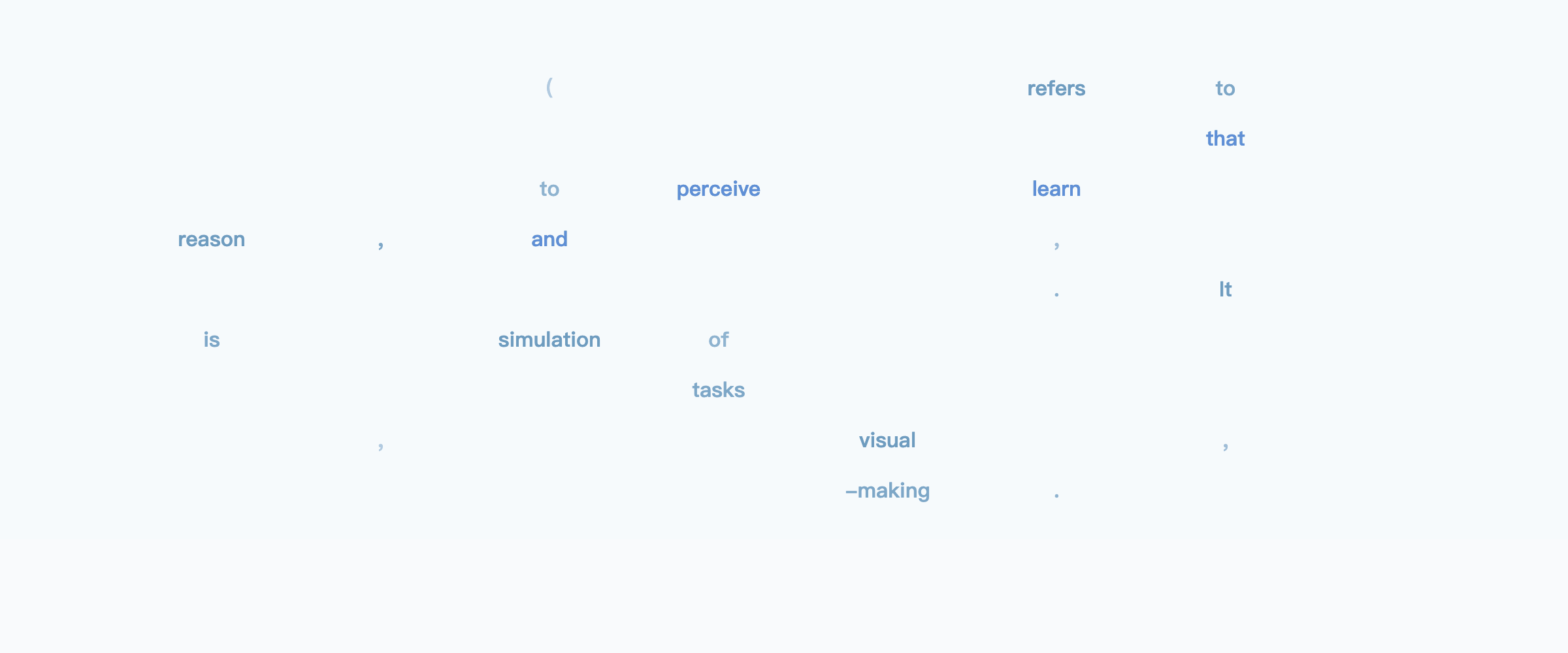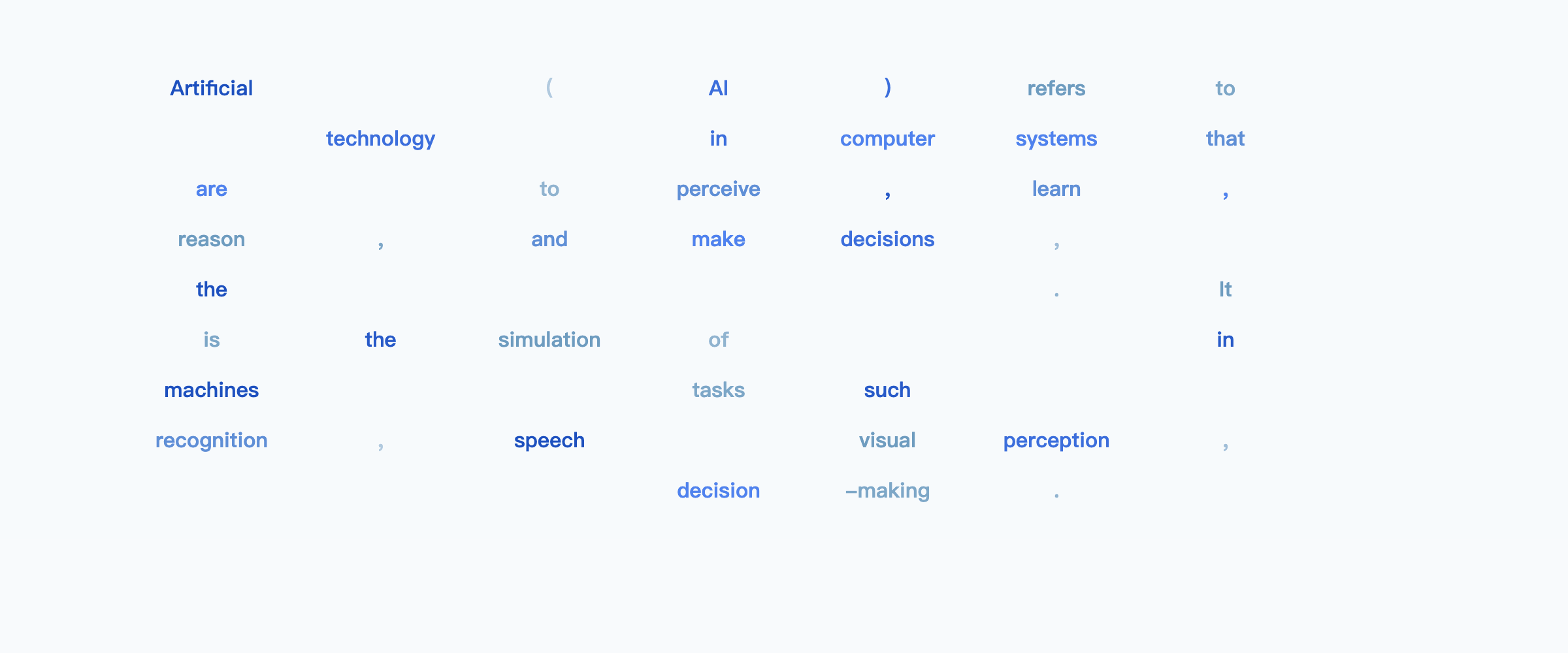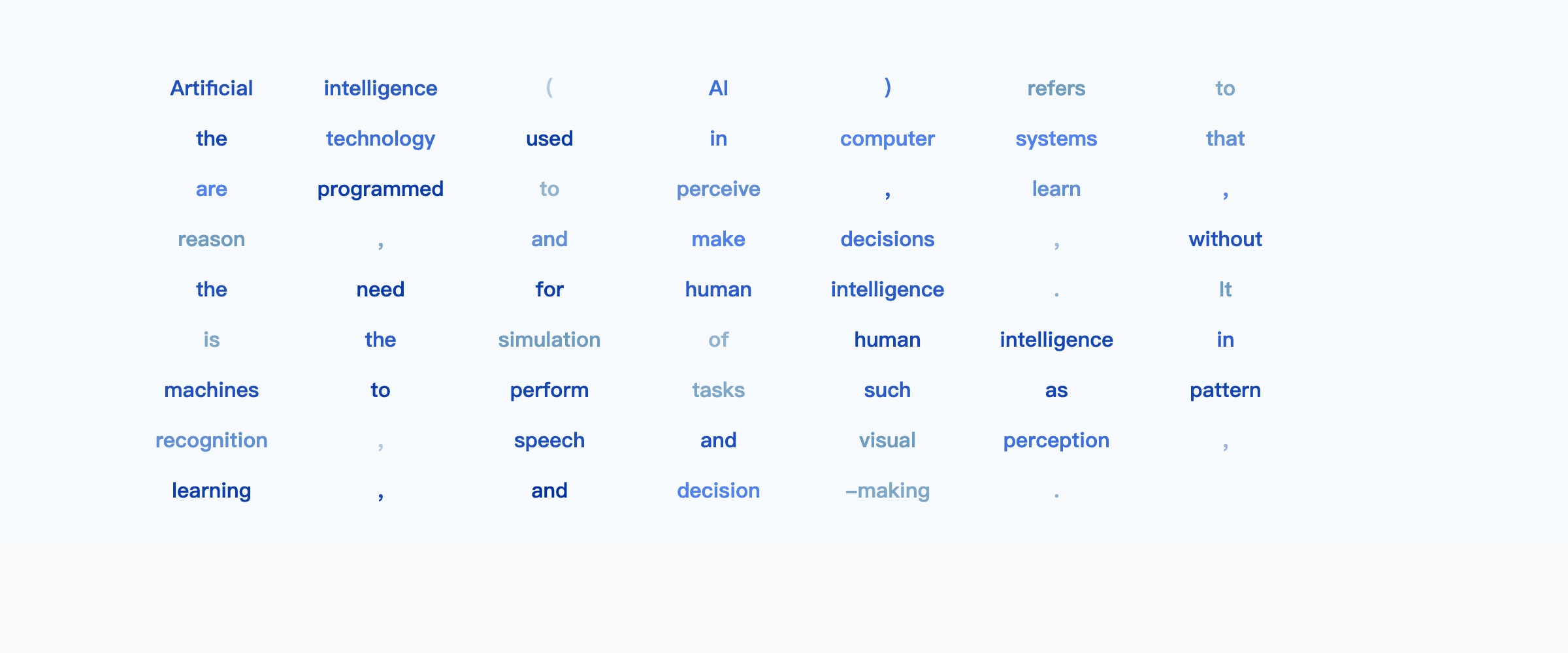
Loosely speaking, you can think about it as starting with an outline and filling in details across the entire output progressively until all the details are filled in.
Diffusion vs Autoregressive Langage Models
Traditional LLMs are autoregressive:
- auto — self, in this case the output is the “self”, the output is also the input to the next token
- regressive — make a prediction, e.g. “linear regression”
LLMs are autoregressive, meaning that all previous output is the input to the next word. So, it generates words one at a time.
That’s how it thinks, one word at a time. It can’t go back and “un-say” a word, it’s one-shotting everything top-to-bottom. The diffusion approach is unique in that it can back out and edit/delete lines of reasoning, kind of like writing drafts.
Thinking Concurrently
Since it’s writing everything at the same time, it’s inherently concurrent. Several thoughts are being developed at the same time globally across the entire output. That means that it’s easier for the model to be consistent and maintain a coherent line of thought.
Some problems benefit more than others. Text like employment agreements is mostly a hierarchy of sections. If you shuffled the sections, the contract would probably retain the same exact meaning. But it still needs to be globally coherent and consistent, that’s critical.
This part resonates with me. There’s clearly trade-offs between approaches. When writing blogs like this, I mostly write it top-to-bottom in a single pass. Because that’s what makes sense to me, it’s how it’s read. But when I review, I stand back, squint and think about it and how it flows globally, almost like manipulating shapes.
Doom Loops
In agents, or even long LLM chats, I’ll notice the LLM starts to go around in circles, suggesting things that already didn’t work, etc. LLaDA offers better global coherence. Because it writes via progressive enhancement instead of left-to-right, it’s able to view generation globally and ensure that the output makes sense and is coherent.
Error Accumulation
Since LLMs are autoregressive, a mistake early on can become a widening gap from reality.
Have you ever had an LLM gaslight you? It’ll hallucinate some fact, but then that hallucination becomes part of it’s input, so it assumes it’s truth and will try to convince you of the hallucinated fact.
That’s partly due to how LLMs are trained. In training, all the input is ground truth, so it learns to trust it’s input. But in inference, the input is it’s previous output, it’s not ground truth but the model treats it like it is. There’s mitigations you can do in post-training, but it’s a fundamental flaw in LLMs that must be faced.
LLaDA is free from this problem, because it’s trained to re-create the ground truth, not trust it unconditionally.
Problem: It’s Still Autoregressive
In practice, I’m not sure how much this global coherence is beneficial. For example, if you have a turn-based chat app, like ChatGPT, the AI answers are still going to depend on previous output. Even in agents, a tool call requires that the AI emit a tool call and then continue (re-enter) with the tool output as input to process it.
So with our current AI applications, we would immediately turn these diffusion models into autoregressive models, effectively.
We also started producing reasoning models (o3, R1, S1). In the reasoning
traces, the LLM allows itself to make mistakes by using a passive unconvinced voice in the <think/> block prior to
giving it’s final answer.
This effectively gives the LLM the ability to think globally for better coherence.
Not A Problem: Fixed Width
Initially I assumed this could only do fixed-width output. But it’s pretty easy to see how that’s not
the case. Emitting a simple <|eot|> token to indicate the end of text/output is enough to get
around this.
New Approaches
LLaDA’s biggest contribution is that it succinctly showed what part of LLMs do the heavy lifting — the language modeling.
Autoregressive modeling (ARM) is an implementation of maximum likelihood estimation (MLE). LLaDA showed that this is functionally the same as [KL divergence][kl], which is what LLaDA used. Any approach that models the probability relationships between tokens will work just as well.
There will be more approaches, with new & different trade-offs.
Conclusion
Watch this space. Keep an open mind. We may see some wild shifts in architecture soon. Maybe it’s diffusion models, maybe it’s some other equivalent architecture with a new set of trade-offs.